ş··Őč4
¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»ĂáĹСŇ÷ӹҵŃÇá»Ă
¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă
ˇŇĂČÖˇÉҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă
ÍŃąŕ»çąŕ»éŇËÁŇ¢ͧ˘éÍĘĂŘ»§ŇąÇÔ¨ŃÂąŃ鹡çŕľ×čÍăËéŕˇÔ´¤ÇŇÁĂŮé
¤ÇŇÁŕ˘éŇ㨷Őč¨ĐĘŇÁŇöşĂĂÂŇ ͸ԺŇ µĹÍ´¨ą¤Çş¤ŘÁĘÔ觵čҧćä´éąŃéą
¤čŇʶԵԷŐčąÓÁŇăŞéşčÍÂÁҡ ¤×Í ¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ě (rxy ) «Öč§ăŞéä´éˇŃşµŃÇá»Ă x
áĹĐ y ·ŐčÁŐÁҵáŇĂÇŃ´áşşÍŃąµĂŔҤ˘Öéąä»
áµčÂѧÁŐ¤čŇʶԵÔÍŐˇËĹҵŃÇ·ŐčăŞéËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă·ŐčÍÂŮčăąŕ§×č͹䢷ŐčµčҧÍ͡ä»
ˇčÍą·Őč¨Đ͸ԺŇÂĂŇÂĹĐŕÍŐ´˘Í§Ę¶ÔµÔ·ŐčăŞéËҤÇŇÁ¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»ĂąŃéą
ŕľ×čÍăËéŕˇÔ´¤ÇŇÁŕ˘éŇă¨ăąˇŇĂŕĹ×͡ăŞéʶԵÔŕľ×čÍČÖˇÉҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă·ŐčŞŃ´ŕ¨ą˘Öéą
¨Ö§ÁŐ¤ÇŇÁ¨Óŕ»çąµéͧŕ˘éŇă¨ăąŕĂ×čͧÁҵáŇĂÇŃ´˘Í§µŃÇá»Ă «Öč§ĘĂŘ»ä´é ´Ń§ąŐé
ˇŇĂáşč§»ĂĐŕŔ·˘Í§˘éÍÁŮŵŇÁÁҵáŇĂÇŃ´ áşč§ŕ»çą
1 ÁҵáŇĂÇŃ´áşşąŇÁşŃѵÔ(Nominal
data ) ŕ»çąˇŇèÓṡĹѡɳТͧ˘éÍÁŮĹ·Őčä´é Í͡ŕ»çą»ĂĐŕŔ·µčҧćËĂ×Íŕ»çąľÇˇć
â´Â¨Ń´ĹѡɳзŐčŕËÁ×ÍąˇŃąäÇé´éÇ¡ѹ ŕŞčą µŃÇá»Ă ŕľČ ŕŞ×éÍŞŇµÔ Ę¶ŇąŔŇľĘÁĂĘ ŕ»çąµéą
ˇŇèÓṡĹѡɳТͧ˘éÍÁŮŢͧµŃÇá»Ăŕ»çą 2 ĹѡɳĐ
ŕĂŐ¡ÇčҵŃÇá»Ă·ÇÔÇÔŔҤ (Dichotomous Variable) ÁŐĂٻẺ㹡ŇèÓṡ·ŐčᵡµčҧˇŃąä´é
2 ĹѡɳР¤×Í µŃÇá»Ă·ÇÔÇÔŔҤá·é (True dichotomous
Variable) áĹеŃÇá»Ă·ÇÔÇÔŔҤ¨ÓṡµŇÁࡳ±ě(Artificially
dichotomous Variable) â´ÂľÔ¨ŇóҨҡࡳ±ěˇŇèÓṡ·ŐčÁŐÍÂŮčáĹéÇ
ˇŃşŕˇł±ě·ŐčµéͧĘĂéҧ˘Öéą ¶éŇࡳ±ě㹡ŇĂáşč§µŃÇá»ĂÍ͡ŕ»çą 2 ĹѡɳĐ
ŕ»çąŕˇł±ě·ŐčÁŐÍÂŮčáĹéÇŕŞčą µŃÇá»ĂŕľČ áşč§ŕ»çą ËÔ§áĹĐŞŇÂ
ˇç¨Ń´ÇčŇŕ»çą·ÇÔÇÔŔҤá·é áµč¶éŇŕ»çąŕˇł±ě·ŐčµéͧĘĂéҧ˘ÖéąŕŞčąˇŇĂĘÍşä´é - µˇ˘Í§ąŃˇŕĂŐÂąˇç¨Ń´ÇčŇŕ»çą·ÇÔÇÔŔҤ¨ÓṡµŇÁࡳ±ě
2 ÁҵáŇĂÇŃ´áşşÍŃą´Ńş(Ordinal
data ) ŕ»çąˇŇáÓËą´ĹѡɳТͧ˘éÍÁŮĹ·Őčä´é Í͡ŕ»çąÍŃą´Ńş·ŐčşÍˇ¤ÇŇÁÁҡąéÍÂĂĐËÇčҧˇŃąä´é
ŕŞčąĹÓ´Ńş·Őč˘Í§ąŃˇŕĂŐÂąÁŇĂÂŇ·´Ő
¤čŇĹÓ´Ńş·Őč 1 , 2 , 3 ĘŇÁŇöşÍˇä´éÇčŇă¤ĂÁŇĂÂŇ·´ŐˇÇčŇă¤Ă
áµčäÁčĘŇÁŇöşÍˇä´éÇčҤą·Őčä´éÁŇĂÂŇ·´ŐĹÓ´Ńş·Őč 1 ´ŐˇÇčŇĹÓ´Ńş·Őč
2 ÍÂŮčŕ·čŇäĂ
áĹĐäÁčĘŇÁŇöşÍˇä´éÇčҤÇŇÁᵡµčҧĂĐËÇčҧ¤ą·Őčä´éÁŇĂÂŇ·´ŐĹÓ´Ńş·Őč 1áĹĐ 2
¨Đŕ·čҡѺ¤ÇŇÁᵡµčҧĂĐËÇčҧ¤ą·Őčä´éÁŇĂÂŇ·´ŐĹÓ´Ńş·Őč 2 áĹĐ 3 ËĂ×ÍŞčǧ¤ÇŇÁËčҧ˘Í§¤čҵŃÇá»ĂáµčĹФčŇäÁčŕ·čҡѹ
3 ÁҵáŇĂÇŃ´áşşÍŃąµĂŔҤ(Interval
data ) ŕ»çąˇŇáÓËą´µŃÇŕŢăËéˇŃşĹѡɳТͧ˘éÍÁŮŵŇÁ¤ÇŇÁÁҡąéÍÂ
â´ÂµŃÇŕŢ·ŐčˇÓËą´ĘŇÁŇöşÍˇ¤ÇŇÁÁҡąéÍÂĂĐËÇčҧˇŃąáĹéÇÂѧÁŐŞčǧËčҧĂĐËÇčҧ¤čŇ·Őčŕ·čҡѹ´éÇÂ
áµč¤čŇČŮąÂě·ŐčˇÓËą´µŇÁÁҵáŇĂÇŃ´ąŐéäÁčăŞčČŮąÂěá·é µŃÇÍÂčҧ ŕŞčą ¤Đáąą
ÍŘłËŔŮÁÔ ŕ»çąµéą ¤čҢͧÍŘłËŔŮÁÔ 80°C Ę٧ˇÇčŇÍŘłËŔŮÁÔ 50 °C ÍÂŮč 30°C áµčÍŘłËŔŮÁÔ 0 °C ÁÔä´éá»ĹÇčŇäÁčÁŐ¤ÇŇÁĂéÍą
¤ÇŇÁ¨ĂÔ§ÁŐ¤ÇŇÁĂéÍąĂдѺ˹Öč§áµč¶ŮˇĘÁÁصÔăËéŕ»çą 0 °C
4. ÁҵĂҡŇĂÇŃ´áşşÍѵĂŇĘčÇą (ratio data) ŕ»çąˇŇáÓËą´µŃÇŕŢăËéˇŃşĹѡɳТͧ˘éÍÁŮĹŕ´ŐÂǡѺÁҵáŇĂÇŃ´áşşÍŃąµĂŔҤ
áµčÁҵáŇĂÇŃ´ĂĐ´ŃşąŐé¨ĐÁŐ¤čŇ 0 ·Őčá·é¨ĂÔ§´éÇ ŕŞčą ÍŇÂŘ
ĂŇÂä´é ąéÓ˹ѡ ĘčÇąĘ٧ ŕ»çąµéą ĘčÇąĘ٧ 0 ŕ«ąµÔŕÁµĂˇçá»ĹÇčŇäÁčÁŐ¤ÇŇÁĘ٧ŕĹÂ
ŕľ×čÍăËéŕËçąŔŇľĂÇÁ˘Í§Ę¶ÔµÔ·ŐčăŞé㹡ŇĂËҤÇŇÁĘŃÁľŃą¸ě
¨Ö§˘Íŕʹ͵ŇĂҧĘĂŘ»ĂĐŕşŐÂşÇÔ¸ŐÇŃ´¤ÇŇÁĘŃÁľŃą¸ě¨ÓṡµŇÁÁҵĂÇŃ´µŃÇá»ĂˇčÍąáĹéǵŇÁ´éÇÂĂŇÂĹĐŕÍŐ´˘Í§áµčĹĐÇÔ¸ŐµčÍä»
ĘĂŘ»ĂĐŕşŐÂşÇÔ¸ŐÇŃ´¤ÇŇÁĘŃÁľŃą¸ě¨ÓṡµŇÁÁҵĂÇŃ´µŃÇá»Ă
|
ÁҵĂÇŃ´µŃÇá»Ă |
ÁҵĂÇŃ´µŃÇá»Ă |
|||
|
|
·ÇÔÇÔŔҤá·é |
·ÇÔÇÔŔҤ¨ÓṡµŇÁࡳ±ě |
ÍŃą´Ńş |
ÍŃąµĂŔҤ/ÍѵĂŇĘčÇą |
|
·ÇÔÇÔŔҤá·é ( TRUE
DICHOTOMUS) ·ÇÔÇÔŔҤ¨ÓṡµŇÁࡳ±ě (ARTIFICIAL DICHOTOMUS) ÍŃą´Ńş
ÍŃąµĂŔҤ/ÍѵĂŇĘčÇą |
Ø Ø rrb rpb |
rt e t rrb rbis |
rsr ,τ |
rxy |
1.
ĘŃÁ»ĂĐĘÔ·¸Ôě żŐ ( Phi correlation)
ŕÁ×č͵éͧˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă·ŐčÁŐÁҵáŇĂÇŃ´ŕ»çą·ÇÔÇÔŔҤá·é·Ń駤Ůč
ËĂ×͵ŃÇËąÖč§ŕ»çą·ÇÔÇÔŔҤá·é ÍŐˇµŃÇËąÖč§ŕ»çą·ÇÔÇÔŔҤ¨ÓṡµŇÁࡳ±ě
¨ĐµéͧăŞéĘŃÁ»ĂĐĘÔ·¸ÔěżŐ (Ø)«Ö觨Đä´é˘ąŇ´¤ÇŇÁĘŃÁľŃą¸ěÇčŇÁŐÁҡąéÍÂŕľŐ§㴠ˇŇĂËҤÇŇÁĘŃÁľŃą¸ě˘Í§ĘͧµŃÇá»ĂŕŞčąąŐéÍҨËŇä´éâ´ÂăŞéʶԵÔ
c2 áµč c2
¨ĐşÍˇä´éáµčŕľŐ§ÇčŇÁŐ¤ÇŇÁĘŃÁľŃą¸ěËĂ×ÍäÁčÁŐ¤ÇŇÁĘŃÁľŃą¸ěŕ·čŇąŃéą
äÁčä´éşÍˇ˘ąŇ´¤ÇŇÁĘŃÁľŃą¸ě
ĘٵĂ
![]()
·´ĘÍş¤ÇŇÁÁŐąŃÂĘÓ¤Ńâ´ÂăŞé c2 ËĂ×Í t-test
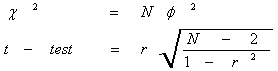
µŃÇÍÂčҧ ˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧŕľČˇŃşˇŇĂä»âçŕĂŐÂą
|
ˇŇĂä»âçŕĂŐÂą |
ŕľČ |
ĂÇÁ |
|
|
|
ŞŇÂ |
ËÔ§ |
|
|
ĘŇ äÁčĘŇ |
10 (a) 40 (b) |
20 (c) 42 (d) |
30 82 |
|
|
50 |
62 |
112 |
![]()
![]() = (40r20)
- (10r42)
= (40r20)
- (10r42)
√ 50 r82r30r62
![]() =
380
=
380
2761.52
=
0.1376
µŃÇÍÂčҧÍ×čą ŕŞčą
ËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧ°ŇąĐŕČĂÉ°ˇÔ¨ˇŃşˇŇĂä»ŕĹ×͡µŃé§
2.
The Tetracholic coefficient
ŕÁ×č͵éͧˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă·ŐčÁŐÁҵáŇĂÇŃ´ŕ»çą·ÇÔÇÔŔҤâ´Â¨ÓṡµŇÁࡳ±ě
·Ń駤Ůč
ĘٵĂ
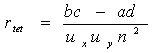
â´Â·Őč Ux
= ¤čҤÇŇÁĘ٧˘Í§ˇŇĂᨡᨧ»ˇµÔÁҵðҹ(ordinate)ł
¨Ř´µŃ´(ĘŃ´ĘčÇą)
¨ŇˇµŃÇá»Ă x
Uy = ¤čҤÇŇÁĘ٧˘Í§ˇŇĂᨡᨧ»ˇµÔÁҵðҹ(ordinate)ł ¨Ř´µŃ´(ĘŃ´ĘčÇą)
¨ŇˇµŃÇá»Ă y
n
= ˘ąŇ´˘Í§ˇĹŘčÁµŃÇÍÂčҧ
µŃÇÍÂčҧ
ˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧ¤ÇŇÁŞÍş˘Í§ËÇŇą ˇŃş¤ÇŇÁŞÍşĽĹäÁé
|
¤ÇŇÁŞÍş ĽĹäÁé(y) |
¤ÇŇÁŞÍş˘Í§ËÇŇą (x) |
||||
|
ŞÍş |
äÁčŞÍş |
ĂÇÁ |
ĘŃ´ĘčÇą |
|
|
|
ŞÍş äÁčŞÍş |
12(a) 32(b) |
21(c) 15(d) |
33 47 |
.42 .58 |
Uy
=.3910 |
|
ĂÇÁ ĘŃ´ĘčÇą |
44 .55 |
36 .45 |
80 |
|
|
|
Ux =.3958 |
|||||
![]() = (32r21)
- (12r15)
= (32r21)
- (12r15)
(.3958)(.3910) r802
![]() = 492
= 492
990.44
=
0.4967
3.
The Rank-biserial correlation
coefficient
ŕÁ×č͵éͧˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă·ŐčÁŐÁҵáŇĂÇŃ´ŕ»çą·ÇÔŔҤáĹĐÍŃą´Ńş
ĘٵĂ
![]()
â´Â·Őč
y1
= ¤čŇŕ©ĹŐčÂÍŃą´Ńş˘Í§µŃÇá»Ăy ¨ŇˇˇĹŘčÁµŃÇá»Ă x=
1
y0 = ¤čŇŕ©ĹŐčÂÍŃą´Ńş˘Í§µŃÇá»Ăy
¨ŇˇˇĹŘčÁµŃÇá»Ă x= 0
µŃÇÍÂčҧ ˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧˇŇ÷ӧҹşéŇąˇŃşÍŃą´Ńş·Őč˘Í§¤Đáąą
|
ˇŇ÷ӧҹşéŇą (x) |
1 0 1 1 1 0 0 1 1 1 |
|
ÍŃą´Ńş·Őč˘Í§¤Đáąą (y) |
1 2 3 4 5 6 7 8 9 10 |
![]()
![]() =
2 ( 5.71 - 5 )
=
2 ( 5.71 - 5 )
10
= 0.142
4.
The Spearman Rank correlation
ŕ»çąÇÔ¸ŐËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă 2 µŃÇ·ŐčÁŐÁҵáŇĂÇŃ´ŕ»çąÍŃą´Ńş·Ń駤Ůč
ÁŐĘٵĂ㹡Ňäӹdz ¤×Í
ĘٵĂ
![]()
â´Â·Őč d = ¤ÇŇÁᵡµčҧĂĐËÇčҧÍŃą´Ńş˘Í§
2 µŃÇá»Ă
n = ¨ÓąÇąˇĹŘčÁµŃÇÍÂčҧ
ʶԵԷ´ĘÍşąŃÂĘÓ¤Ń
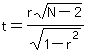
df = n-2
µŃÇÍÂčҧ
ˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧ ˇŇĂăËé¤ĐáąąĘÍşÇÔŞŇĘ¶ÔµÔ ˘Í§ÍҨŇĂÂě 2 ¤ą
|
ąŃˇŕĂŐÂą |
¤ĂŮ |
d |
d2 |
|
¤ą·Őč1
¤ą·Őč2 |
|||
|
¤Đáąą ÍŃą´Ńş·Őč
¤Đáąą
ÍŃą´Ńş·Őč |
|||
|
1 2 3 4 5 |
19
1
18
2
17
3
16
3
16
4
14
5
18
2
20
1
15
5
15
4 |
1 0 1 -1 -1 |
1 0 1 1 1 |
ĘٵĂ
![]()
![]() = 1 - 6 r 4
= 1 - 6 r 4
5(25-1)
= 0.8
áĘ´§ÇčҡŇĂăËé¤Đáąą˘Í§¤ĂŮ 2
¤ąÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃąăąĂĐ´ŃşĘ٧
ˇŇĂ·´ĘÍşąŃÂĘÓ¤Ń
H0 : r = 0
H1 : r > 0
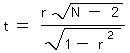
= 0.8
√
5 - 2
√1
- 0.82
= 0.8
(1.732)
0.6
= + 2.30
![]()
 a 0.10
a 0.10
![]() 0
1.63 t (df =5-2
= 3)
0
1.63 t (df =5-2
= 3)
t ¤ÓąÇłÁҡˇÇčҤčŇÇԡĵ áĘ´§ÇčŇ»ŻÔŕʸĘÁÁµÔ°Ňą H0 ąŃ蹤×Í ˇŇĂăËé¤Đáąą˘Í§¤ĂŮ 2 ¤ąÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃąÍÂčҧÁŐąŃÂĘӤѷҧʶԵԷŐčĂĐ´Ńş 0.10
5.
Kendall’s Tau
ŕÁ×č͵éͧˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă·ŐčÁŐÁҵáŇĂÇŃ´ŕ»çąÍŃą´Ńş·Ń駤Ůč
Ęٵà ![]()
â´Â·Őč ¨ÓąÇą¤ÇŇÁĘÍ´¤Ĺéͧ
¤×ͨӹǹÍŃą´Ńş·Őč·ŐčŕËĹ×Í·ŐčĘ٧ˇÇčŇÍŃą´Ńş·Őč¨Ń´ŕĂŐ§¨ŇˇµŃÇá»ĂY ŕ·ŐÂşµŇÁÍŃą´Ńş·Őč¨ŇˇąéÍÂä»Áҡ˘Í§µŃÇá»ĂX
¨ÓąÇą¤ÇŇÁĽˇĽŃą
¤×ͨӹǹÍŃą´Ńş·Őč·ŐčŕËĹ×͵čÓˇÇčŇÍŃą´Ńş·Őč¨Ń´ŕĂŐ§¨ŇˇµŃÇá»ĂY ŕ·ŐÂşµŇÁÍŃą´Ńş·Őč¨ŇˇąéÍÂä»Áҡ˘Í§µŃÇá»ĂX
p = ĽĹĂÇÁ˘Í§¨ÓąÇą¤ÇŇÁĘÍ´¤Ĺéͧ
q = ĽĹĂÇÁ˘Í§¨ÓąÇą¤ÇŇÁĽˇĽŃą
n = ˘ąŇ´˘Í§µŃÇÍÂčҧ
µŃÇÍÂčҧ ¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧÍŃą´Ńş·Őč˘Í§¨ÓąÇąĘĘ.áĹĐÍŃą´Ńş·Őč˘Í§şŃŞŐĂŇÂŞ×čÍ
|
Ş×čÍľĂä |
ÍŃą´Ńş·Őč˘Í§¨ÓąÇąĘĘ.(x) |
ÍŃą´Ńş·Őč˘Í§ şŃŞŐĂŇÂŞ×čÍ(y) |
¨ÓąÇą¤ÇŇÁ ĘÍ´¤Ĺéͧ |
¨ÓąÇą¤ÇŇÁ ĽˇĽŃą |
|
ä·ÂĂѡä·Â »ĂЪҸԻ»ŃµÂě ŞŇµÔä·Â ŞŇµÔľŃ˛ąŇ ¤ÇŇÁËÇѧăËÁč »ĂЪҡĂä·Â ŕĘĂŐ¸ĂĂÁ ¶Ôčąä·Â |
1 2 3 4 5 6 7 8 |
3 1 2 4 7 8 5 6 |
5 6 5 4 1 0 1 0 |
2 0 0 0 2 2 0 0 |
|
P=22
Q=6 |
||||
![]()
![]() =
22 - 6
=
22 - 6
8(8 -1)/2
=
16
=
0.57
28
6.
The Point Biserial Correlation
ŕÁ×č͵éͧˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă·ŐčÁŐÁҵáŇĂÇŃ´ŕ»çą·ÇÔÇÔŔҤá·éáĹĐÍŃąµĂŔҤ/ÍѵĂŇĘčÇą
Ęٵà 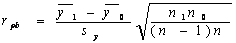
![]() â´Â·Őč y1
= ¤čŇŕ©ĹŐč¢ͧ˘éÍÁŮĹĂĐËÇčҧµŃÇá»Ăy ¨ŇˇˇĹŘčÁµŃÇá»Ă x=
1
â´Â·Őč y1
= ¤čŇŕ©ĹŐč¢ͧ˘éÍÁŮĹĂĐËÇčҧµŃÇá»Ăy ¨ŇˇˇĹŘčÁµŃÇá»Ă x=
1
![]() y0
= ¤čŇŕ©ĹŐč¢ͧ˘éÍÁŮĹĂĐËÇčҧµŃÇá»Ăy ¨ŇˇˇĹŘčÁµŃÇá»Ă x=
2
y0
= ¤čŇŕ©ĹŐč¢ͧ˘éÍÁŮĹĂĐËÇčҧµŃÇá»Ăy ¨ŇˇˇĹŘčÁµŃÇá»Ă x=
2
SY
= ĘčÇąŕşŐč§ູÁҵðҹ˘Í§˘éÍÁŮŨҡµŃÇá»Ă
y ·Ńé§ËÁ´
µŃÇÍÂčҧ ˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧŕľČˇŃş¤ĐṹʶԵÔ
|
ŕľČ |
Ş |
Ş |
Ş |
Ş |
Ş |
|
|
|
|
|
|
¤ĐáąąĘ¶ÔµÔ |
15 |
19 |
12 |
9 |
18 |
11 |
16 |
19 |
13 |
7 |
![]()
![]()
![]() = 14.6 – 13.2 5 r 5
= 14.6 – 13.2 5 r 5
4.2
Ö 9r10
= 0.33 r .52
= 0.17
7.
The Biserial Correlation
ŕÁ×č͵éͧˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă·ŐčÁŐÁҵáŇĂÇŃ´ŕ»çą·ÇÔŔҤµŇÁࡳ±ěáĹĐÍŃąµĂŔҤ/ÍѵĂŇĘčÇą
Ęٵà 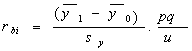
â´Â·Őč y1 = ¤čŇŕ©ĹŐč¢ͧ˘éÍÁŮĹĂĐËÇčҧµŃÇá»Ăy
¨ŇˇˇĹŘčÁµŃÇá»Ă x= 1
y0 = ¤čŇŕ©ĹŐč¢ͧ˘éÍÁŮĹĂĐËÇčҧµŃÇá»Ăy
¨ŇˇˇĹŘčÁµŃÇá»Ă x= 0
p = ĘŃ´ĘčÇą˘Í§¤ą·ŐčÍÂŮč㹡ĹŘčÁµŃÇá»Ă
x= 1
q = ĘŃ´ĘčÇą˘Í§¤ą·ŐčÍÂŮč㹡ĹŘčÁµŃÇá»Ă
x= 0
u = ¤čҤÇŇÁĘ٧˘Í§ˇŇĂᨡᨧ»ˇµÔÁҵðҹ(ordinate)ł ¨Ř´µŃ´(ĘŃ´ĘčÇą)
SY = ĘčÇąŕşŐč§ູÁҵðҹ˘Í§˘éÍÁŮŨҡµŃÇá»Ă
y ·Ńé§ËÁ´
µŃÇÍÂčҧ ˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧˇŇõͺ˘éÍ 3 ˇŃş¤ĐáąąĂÇÁ
|
ˇŇõͺ˘éÍ3 |
¤ĐáąąĂÇÁ |
ˇŇõͺ˘éÍ3 |
¤ĐáąąĂÇÁ |
ˇŇõͺ˘éÍ3 |
¤ĐáąąĂÇÁ |
|
1 |
21 |
1 |
38 |
0 |
26 |
|
1 |
35 |
1 |
36 |
0 |
35 |
|
1 |
37 |
0 |
31 |
0 |
36 |
|
1 |
32 |
0 |
28 |
0 |
21 |
|
1 |
22 |
0 |
21 |
0 |
23 |
|
1 |
28 |
0 |
22 |
0 |
25 |
|
1 |
39 |
0 |
27 |
0 |
27 |
|
1 |
40 |
0 |
33 |
0 |
26 |
|
|
|
|
|
0 |
25 |
![]()
![]()
![]() =
(32.8 - 27.06) r ( 0.4 r 0.6)
=
(32.8 - 27.06) r ( 0.4 r 0.6)
6.28
0.3863
= 0.91r 0 .621 = 0.565
8. Correlation coefficient
ĘËĘŃÁľŃą¸ěÍÂčҧ§čŇ (Correlation) ŕ»çąˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»ĂµŃé§áµč 2 µŃǢÖéąä»ÇčŇÁŐ¤ÇŇÁĘŃÁľŃą¸ěŕˇŐčÂǢéͧˇŃąËĂ×ÍäÁčĹѡɳĐă´
áĹФÇŇÁĘŃÁľŃą¸ěˇŃąÁҡąéÍÂŕľŐ§ă´
ĘËĘŃÁľŃą¸ěÁŐËĹŇÂŞąÔ´
·ŐčĂŮé¨ŃˇˇŃą·ŃčÇä»ä´éáˇč ĘËĘŃÁľŃą¸ěŕŞÔ§ŕ´ŐÂÇ (Simple Correlation) ĘËĘŃÁľŃą¸ěľËؤٳ
(
Multiple Correlation) ąÍˇ¨ŇˇąŃ鹨ҡĘ˾ѹ¸ěąŐéÂѧÇÔŕ¤ĂŇĐËěµčÍä»ä´éÍŐˇŕŞčąˇŇĂÇÔŕ¤ĂŇĐË춴¶ÍÂ
(Regression Analysis)
ĘËĘŃÁľŃą¸ěŕŞÔ§ŕ´ŐčÂÇ
ŕ»çąˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă
2
µŃÇ
áĹĐĘÁÁµÔÇčŇÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃąăąĹѡɳĐŕĘ鹵ç
¤ÇŇÁĘŃÁľŃą¸ě˘Í§µŃÇá»Ă˘Í§·Ńé§ĘͧÍҨ¨ĐĘŃÁľŃą¸ěˇŃąăą 4 ĹѡɳР¤×Í
ĹѡɳзŐč 1
ŕ»çąˇŇĂĘŃÁľŃą¸ěˇŃąŕŞÔ§şÇˇÍÂčҧĘÁşŮĂłě ÁŐĹѡɳĐá»ĂĽŃąµŇÁˇŃą ŕÁ×čÍ X ŕľÔčÁ Y
ˇç¨ĐŕľÔčÁ˘Öéą´éÇ ¶éŇ
X Ŵŧ Y ˇç¨ĐŴŧ´éÇÂ
áĹĐŕľÔčÁ˘ÖéąËĂ×ÍŴŧăąÍѵĂŇĘčÇą·Ő褧·Őč ´Ń§ĹѡɳР1
ĹѡɳзŐč 2 ŕ»çąˇŇĂĘŃÁľŃą¸ěˇŃąŕŞÔ§ĹşÍÂčҧĘÁşŮĂłě
ăąĹѡɳмˇĽŃąˇŃą ŕÁ×čÍ X ŕľÔčÁ Y ˇç¨ĐŴŧ´Ń§ĹѡɳР2
ĹѡɳзŐč 3
ŕ»çąˇŇĂĘŃÁľŃą¸ěˇŃąáşşäÁčĘÁşŮĂłě
«Ö觨Đŕ»çąĹѡɳĐá»ĂĽŃąµŇÁˇŃąËĂ×ÍĽˇĽŃąˇŃąä´é áµčÁŐĹѡɳĐĘŃÁľŃą¸ěµčÓ ˇŇĂĘŃÁľŃą¸ě¨ĐˇĂШŇ¡ѹ
áµčˇçÂѧŕˇŇСĹŘčÁˇŃą·ÓăËéŕËçąÇčŇŕ»çąŕĘ鹵ç ´Ń§ĹѡɳР3
![]() ĹѡɳзŐč 4
ŕ»çąĹѡɳзŐčäÁčĘŃÁľŃą¸ěˇŃąŕ»çąŕĘ鹵ç ¤čҢͧ X áĹĐ Y ·ŐčµŃ´ˇŃąˇĂШѴˇĂШŇ·ŃčÇä»
áĹĐÁŐĹѡɳФĹéҨĐŕ»çąÇ§ˇĹÁ äÁčĘŇÁŇöşÍˇ¤ÇŇÁĘŃÁľŃą¸ě˘Í§ X áĹĐ Y ä´éÇčŇŕ»çą·Ôȷҧă´
´Ń§ĹѡɳР4
ĹѡɳзŐč 4
ŕ»çąĹѡɳзŐčäÁčĘŃÁľŃą¸ěˇŃąŕ»çąŕĘ鹵ç ¤čҢͧ X áĹĐ Y ·ŐčµŃ´ˇŃąˇĂШѴˇĂШŇ·ŃčÇä»
áĹĐÁŐĹѡɳФĹéҨĐŕ»çąÇ§ˇĹÁ äÁčĘŇÁŇöşÍˇ¤ÇŇÁĘŃÁľŃą¸ě˘Í§ X áĹĐ Y ä´éÇčŇŕ»çą·Ôȷҧă´
´Ń§ĹѡɳР4
![]() y
y
y
y
![]()
![]()
ĹѡɳР1
x ĹѡɳĐ
2
x
![]()
![]()
![]() y y
y y
![]()
![]()
ĹѡɳР3
x
ĹѡɳР4
x
˘ąŇ´˘Í§¤ÇŇÁĘŃÁľŃą¸ě
˘ąŇ´˘Í§¤ÇŇÁĘŃÁľŃą¸ěÁŐ¤čҨҡ0 ¶Ö§ 1.00 ĘŇÁŇö¨Ń´ĂĐ´Ńş¤ÇŇÁĘŃÁľŃą¸ěä´éâ´Â»ĂĐÁŇł ´Ń§ąŐé
¤ÇŇÁĘŃÁľŃą¸ě·Ň§ĹşÍÂčҧĘÁşŮĂłě
äÁčÁŐ¤ÇŇÁĘŃÁľŃą¸ě
¤ÇŇÁĘŃÁľŃą¸ě·Ň§şÇˇÍÂčҧĘÁşŮĂłě
|
ĹşĂĐ´ŃşĘ٧ |
ĹşĂĐ´ŃşˇĹҧ |
ĹşĂĐ´ŃşµčÓ |
şÇˇĂĐ´ŃşµčÓ |
şÇˇĂĐ´ŃşˇĹҧ |
şÇˇĂĐ´ŃşĘ٧ |
|
-1.00
-0.50
|
0
+0.50
+1.00 |
||||
Ęٵ÷ŐčăŞé㹡Ňäӹdz ¤čŇ r
r ŕĂŐ¡ÇčŇ Pearson correlation coefficiient , Simple
correlation , Correlation coefficient
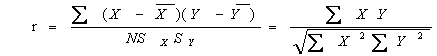
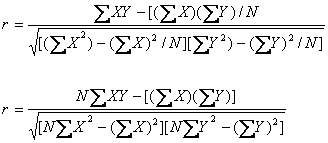
µŃÇÍÂčҧ
¨ŇˇˇŇĂČÖˇÉҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧ¤ÇŇÁĂŮéˇŃş¤ÇŇÁ¤Ô´ŕË繢ͧąŃˇČÖˇÉŇ 5 ¤ą ä´é¤Đáąą¤ÇŇÁĂŮéáĹФÇŇÁ¤Ô´ŕËçą
´Ń§µŇĂҧ ÍÂҡ·ĂŇşÇčŇ ¤ÇŇÁĂŮéˇŃş¤ÇŇÁ¤Ô´ŕËçąĘŃÁľŃą¸ěˇŃąËĂ×ÍäÁč
¶éŇĘŃÁľŃą¸ěĘŃÁľŃą¸ěˇŃąăą·Ôȷҧă´
ˇŇäӹdz ĘÁÁµÔăËé X = ¤Đáąą¤ÇŇÁĂŮé áĹĐ Y = ¤Đáąą¤ÇŇÁ¤Ô´ŕËçą ¨Ń´ĂĐŕşŐÂşŕµĂŐÂÁˇŇĂÇÔŕ¤ĂŇĐËě ´Ń§ąŐé
µŇĂҧ
ˇŇèѴĂĐŕşŐÂşŕµĂŐÂÁˇŇĂÇÔŕ¤ĂŇĐËěĘ˾ѹ¸ěáşş Pearson
![]()
![]() ¤ą·Őč X
Y
X2
Y2
XY
1
5
8
25 64 40
¤ą·Őč X
Y
X2
Y2
XY
1
5
8
25 64 40
2 5
9
25 81
45
3
4
8
16 64
32
4 3
6
9 36
18
5
3
7
9 49
21
![]() ĂÇÁ 20
38
84 294
156
ĂÇÁ 20
38
84 294
156
ˇŇäӹdz¤čŇ r
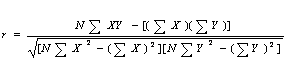
![]() =
5 (156)-(20)(38)
=
5 (156)-(20)(38)
![]() √(5(84)-400) (5(294)-(1444)
√(5(84)-400) (5(294)-(1444)
=
20
![]()
![]() √ (20)(26)
√ (20)(26)
=
0.877
ĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ě ŕ·čҡѺ 0.877
áĘ´§ÇčҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧ¤ÇŇÁĂŮéˇŃş¤ÇŇÁ¤Ô´ŕË繢ͧąŃˇČÖˇÉŇ
ÁŐ¤ÇŇÁĘŃÁľŃą¸ě㹷ҧşÇˇĂĐ´ŃşĘ٧
ˇŇĂ·´ĘÍşąŃÂĘӤѢͧ¤čŇ r
㹡ŇĂÇÔ¨ŃÂąŃéą ËĹѧ¨Ňˇ·Őč¤ÓąÇł¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ěä´éáĹéÇ
áĹеéͧˇŇĂ·Őč¨ĐĘĂŘ»ÇčҵŃÇá»Ă¤ŮčąŃéąÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃą¨ĂÔ§ËĂ×ÍäÁč
¨ĐäÁčľÔ¨ŇĂłŇŕ©ľŇФčŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ě·Őč¤ÓąÇłä´é
ˇĹčŇǤ×Ͷ֧áÁéÇčҨФӹdz¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ěä´é¤čŇËąÖ觫Ö觤čÍą˘éҧĘ٧
ŕŞčą .70 ˘Öéąä» ˇç¨ĐÂѧäÁčĘĂŘ»ÇčҵŃÇá»Ă 2 µŃÇąŃéąÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃą¨ąˇÇčҨĐÁŐˇŇĂ·´ĘÍşąŃÂĘӤѡčÍą (Test of
significance) «Ö觵Ńé§ H0 áĹĐ H1
´Ń§ąŐé H0 : r = 0, H1 : r ¹ 0 (Welkowitz. 1971 : 158)
ÇÔ¸Ő·ÓĘÍşÁŐ 2 ÇÔ¸Ő
¤×ÍăŞéµŇĂҧĘÓŕĂ稷ŐčÁŐŞ×čÍÇčҤčŇÇԡĵ˘Í§ĘËĘŃÁľŃą¸ěáşşŕľŐÂĂěĘŃą
ËĂ×ÍăŞéˇŇĂ·´ĘÍş¤čŇ·Ő (t-test) ¨ŇˇĘٵĂ
r á·ą ¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ě·Őč¤ÓąÇłä´é
N á·ą ¨ÓąÇą˘éÍÁŮĹËĂ×ͨӹǹ¤ą
ÇÔ¸ŐˇŇĂ·´ĘÍşÁŐ˘Ń鹵͹´Ń§ąŐé
(1) ¤ÓąÇł¤čŇ t ¨ŇˇĘٵĂ
(2) ŕ»Ô´ Table ËҤčŇ t ·Őč df = N-2
ł ĂĐ´ŃşąŃÂĘӤѷҧʶԵԷŐčµŃé§äÇé
(3) ŕ»ĂŐÂşŕ·ŐÂş¤čŇ t ·Őč¤ÓąÇłä´éˇŃş¤čŇ t ·Őčŕ»Ô´¨ŇˇµŇĂҧ
¶éŇ t ¤ÓąÇł > t µŇĂҧ
áĘ´ÇčҤčŇ r ·Őč¤ÓąÇłä´éÁŐąŃÂĘӤѷҧʶԵÔ
á»Ĺ¤ÇŇÁËÁŇÂä´éÇčŇ µŃÇá»Ă 2
µŃÇąŃéąÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃąÍÂčҧÁŐąŃÂĘӤѷҧʶԵԷŐčĂĐ´Ńş…
¶éŇ t ¤ÓąÇł < t µŇĂҧ
áĘ´§ÇčҤčŇ r ·Őč¤ÓąÇłä´éäÁčÁŐąŃÂĘӤѷҧʶԵÔ
á»Ĺ¤ÇŇÁä´éÇčŇ µŃÇá»Ă 2
µŃÇąŃéąÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃąÍÂčҧäÁčÁŐąŃÂĘӤѷҧʶԵÔ
µŃÇÍÂčҧˇŇĂ·´ĘÍşąŃÂĘÓ¤Ń
µŃÇÍÂčҧ·Őč….¨§·´ĘÍşąŃÂĘӤѢͧ¤čŇ r ŕÁ×čÍ r = .877
ĘٵĂ
r
= .877 , N = 5
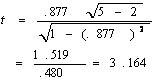
¨ŇˇµŇĂҧ t
·Őč a .10, df = 5-2 = 3, ä´é t = 2.353
t
¤ÓąÇł > t µŇĂҧ áĘ´§ÇčŇ r = .877 ·Őč¤ÓąÇłä´éÁŐąŃÂĘÓ¤Ń·Ň§Ę¶ÔµÔ ąŃ蹤×Í ÁŐ¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧ¤ÇŇÁĂŮéˇŃş¤ÇŇÁ¤Ô´ŕË繢ͧąŃˇČÖˇÉŇ
ÍÂčҧÁŐąŃÂĘӤѷҧʶԵԷŐčĂĐ´Ńş 0.10
ˇŇĂ·´ĘÍş¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă 2 µŃÇ
â´ÂăŞéâ»ĂáˇĂÁ SPSS for
Windows
ˇŇĂ·´ĘÍş¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă
2 µŃÇ
ĘŇÁŇöˇŇĂÇÔŕ¤ĂŇĐËě â´ÂăŞéâ»ĂáˇĂÁ SPSS
for Windows ä´é´Ń§ąŐé
1.
¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă
2 µŃÇ
·ŐčÁŐĂĐ´ŃşˇŇĂÇŃ´ŕ»çą ordinal (ăŞéĘ¶ÔµÔ Spearman
Rank correlation )
2.
¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă
2 µŃÇ
·ŐčÁŐĂĐ´ŃşˇŇĂÇŃ´ŕ»çą interval ËĂ×Í ratio ( ăŞéĘ¶ÔµÔ pearson product moment correlation )
1.1 ăŞé¤ÓĘŃč§
 Statistics
Statistics
Correlate
Bivarriate
¨Đä´éËąéҨÍ
´Ń§ĂŮ»·Őč1
ĂŮ»·Őč
1
ŕĹ×͡ µŃÇá»Ă·ŐčµéͧˇŇĂËҤÇŇÁĘŃÁľŃą¸ěăĘčăą box ˘Í§ variables áĹéÇŕĹ×͡
Spearman 㹡óշŐčµéͧˇŇĂËҤÇŇÁĘŃÁľŃą¸ě˘Í§ 2 µŃÇá»Ă·ŐčÁŐĂĐ´ŃşˇŇĂÇŃ´áşş ordinal ËĂ×ÍŕĹ×͡ Pearson 㹡óշŐčµéͧˇŇĂËҤÇŇÁĘŃÁľŃą¸ě˘Í§
2 µŃÇá»Ă·ŐčÁŐĂĐ´ŃşˇŇĂÇŃ´áşş interval ËĂ×Í
ratio áĹéÇŕĹ×͡ OK ¨Đä´éĽĹĹŃľ¸ěáĘ´§ăąµŇĂҧ·Őč
1-2
µŇĂҧ·Őč 1
Spearman's rho
|
|
|
|
EDUFA |
EDUMA |
|
Spearman's
rho |
EDUFA |
Correlation
Coefficient |
1.000 |
.729 |
| |
|
Sig.
(2-tailed) |
. |
.000 |
| |
|
N |
1408 |
1406 |
| |
EDUMA |
Correlation
Coefficient |
.729 |
1.000 |
| |
|
Sig. (2-tailed) |
.000 |
. |
| |
|
N |
1406 |
1421 |
¨ŇˇµŇĂҧ·Őč 1 ËÁҤÇŇÁÇčŇ
ˇŇĂČÖˇÉҢͧşÔ´Ň ( Edufa
)
ÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŇĂČÖˇÉҢͧÁŇĂ´Ň (Eduma) ÍÂčҧÁŐąŃÂĘӤѷҧʶԵԷŐčĂĐ´Ńş
.01
«Öč§ĘŇÁŇöąÓŕʹͼšŇĂÇÔŕ¤ĂŇĐËě˘éÍÁŮĹ ä´éµŇÁµŇĂҧµčÍ仹Őé
|
µŃÇá»Ă |
Spearman's
rho |
p - value |
|
ˇŇĂČÖˇÉҢͧşÔ´Ň ˇŇĂČÖˇÉҢͧÁŇĂ´Ň |
.956 |
0.000 |
µŇĂҧ·Őč 2 Pearson
correlation
|
|
Total
Expense |
income
of respondent |
|
Pearson
Total Expense Correlation
income of respondent |
1.000 .956 |
.956 1.000 |
|
Sig.
Total Expense ( 1-
tailed )
income of respondent |
. .000 |
.000 . |
|
N
Total Expense
income of respondent |
90 90 |
90 90 |
¨ŇˇµŇĂҧ·Őč 2 ËÁҤÇŇÁÇčŇ ¤čŇăŞé¨čŇ ( Expense ) ÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃş
ĂŇÂä´é˘Í§ĽŮéĂŃşĽÔ´ŞÍş¤ĂÍş¤ĂŃÇ (
income of respondent ) ÍÂčҧÁŐąŃÂĘӤѷҧʶԵԷŐčĂĐ´Ńş
.01
«Öč§ĘŇÁŇöąÓŕʹͼšŇĂÇÔŕ¤ĂŇĐËě˘éÍÁŮĹ ä´éµŇÁµŇĂҧµčÍ仹Őé
|
µŃÇá»Ă |
r |
p - value |
|
¤čŇăŞé¨čŇ -ĂŇÂä´é |
.956 |
0.000 |
ˇŇ÷ӹҵŃÇá»Ă : ˇŇĂÇÔŕ¤ĂŇĐË춴¶Í (Regression Analysis )
ˇŇĂÇÔŕ¤ĂŇĐËěˇŇö´¶ÍÂ
ŕ»çąĘ¶ÔµÔ·ŐčăŞé㹡Ň÷ӹҵŃÇá»ĂÇÔ¸ŐËąÖč§
ŕÁ×čÍÁŐµŃÇá»ĂµéąËĂ×͵ŃÇá»ĂÍÔĘĂĐŕľŐ§µŃÇŕ´ŐÂÇ
áĹеéͧˇŇĂ·´ĘÍşÇčҵŃÇá»ĂµéąąŃéąÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃşµŃÇá»ĂµŇÁÍÂčҧäĂ
㹡óշŐčÁŐµŃÇá»ĂŕľŐ§ 2
µŃÇŕŞčąąŐéˇŇĂÇÔŕ¤ĂŇĐËěˇŇö´¶ÍÂąŐéŕĂŐ¡ÇčŇ Bivariate regression ËĂ×Í Simple
regression ¶éŇ plot
¨Ř´ â´ÂăËé᡹ X ŕ»çą¨ÓąÇą¤ĂŃ駢ͧˇŇĂ仫×éÍĘÔą¤éŇ
áĹĐ᡹ Y ŕ»çą·ŃČą¤µÔ˘Í§ĽŮéşĂÔâŔ¤·ŐčÁŐµčÍËéҧĘĂĂľĘÔą¤éŇ
¨Đä´éĂŮ» Scatter diagram ´Ń§ąŐé
ˇŇĂ Plot ˘éÍÁŮĹ·ŃČą¤µÔ·ŐčÁŐµčÍËéҧĘĂĂľĘÔą¤éŇáĹШӹǹ¤ĂŃ駷ŐčĽŮéşĂÔâŔ¤ä»«×éÍĘÔą¤éŇ
![]() Y ( ·ŃČą¤µÔ )
Y ( ·ŃČą¤µÔ )
X
X
X X
X
X
X
X
X
![]() X ¨ÓąÇą¤ĂŃ駷Őč仫×éÍĘÔą¤éŇ
X ¨ÓąÇą¤ĂŃ駷Őč仫×éÍĘÔą¤éŇ
ˇŇĂľÔ¨ŇĂłŇ Scatter
diagram ¨Đ·ÓăËéĘŇÁŇöÁͧŕËçą
“ ĂŮ»Ăčҧ ” ˘Í§¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă·Ńé§
2 µŃÇä´é ¨ĐĘѧࡵä´éÇčŇŕÁ×č͵ŃÇá»Ă X ŕľÔčÁ˘Öéą µŃÇá»Ă Y ˇçÁŐáąÇâąéÁŕ»çą¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§ŕĘ鹵ç(Linear
relationship )ŕ·¤ąÔ¤ăąˇŇĂ Fit µŃÇáşş¨ÓĹͧ (
Model ) ăËéĘŇÁŇö͸ԺŇ¢éÍÁŮĹ (Data) ä´éąŃéąŕĂŐ¡ÇčŇŕ·¤ąÔ¤
Least - square ŕ·¤ąÔ¤ąŐé¨ĐˇÓËą´ŕĘ鹵ç·Őč´Ő·ŐčĘŘ´ â´Â·ŐčŕÁ×čÍĹҡŕĘ鹵çŕĘéąąŐéĂĐËÇčҧ Plot
şą Scatter diagram áĹéÇ
ĽĹĂÇÁ˘Í§¤ÇŇÁᵡµčҧĂĐËÇčҧ¨Ř´·Řˇ¨Ř´·ŐčËčҧ¨ŇˇŕĘ鹵çĂÇÁˇŃą¨ĐµéͧÁŐ¤čŇąéÍ·ŐčĘŘ´
ŕĘ鹵çŕĘéą·Őč´Ő·ŐčĘŘ´ąŐéŕĂŐ¡ÇčŇ ŕĘéą Regression line ËĂ×Í
ŕĘéąĘÁˇŇö´¶Í ĂĐÂеŃ駩ҡĂĐËÇčҧ¨Ř´·Őč plot ˇŃşŕĘ鹵ç
ŕĂŐ¡ÇčŇ Error ĂĐÂĐËčҧ¨Ňˇ¨Ř´·Řˇ¨Ř´·Őč Plot ˇŃşŕĘ鹵çŕÁ×čÍ¡ˇÓĹѧ 2 áĹĐąÓÁҺǡĂÇÁˇŃąŕĂŐ¡ÇčŇĽĹĂÇÁ˘Í§¤ÇŇÁ¤ĹŇ´ŕ¤Ĺ×č͹¡ˇÓĹѧĘͧ
( Sum of squared errors ) å ei2 ¨ĐµéͧÁŐ¤čŇąéÍ·ŐčĘŘ´
ŕĘéą Regression line ·Őč´Ő·ŐčĘŘ´¨Ö§¶ŮˇŕĂŐ¡ÇčŇ The regression line of Y on X ĘÁˇŇĂ Bivariate
regression ˘Í§ŕĘ鹵ç regression line ĘŇÁŇöŕ˘ŐÂąä´é´Ń§ąŐé
![]()
U = a + bC + ei
â´Â·Őč U = µŃÇá»ĂµŇÁ
( Dependent or criterion variable ) ËĂ×ÍÂÍ´˘ŇÂ
C = µŃÇá»ĂÍÔĘĂĐ
( Independent or predictor variable ) µŃÇ·Őč 1
a = ¤čҤ§·Őč (
Intercept of the line )
b = ¤čҤÇŇÁŞŃą˘Í§ŕĘéą
( Slope of the line )
eI = ¤ÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍą·ŐčŕˇÔ´˘Öéąŕą×čͧ¨Ňˇ Y ᵡµčҧ¨Ňˇ Y
ˇŇĂ»ĂĐÁŇł¤čŇ a áĹĐ b ´éÇ a áĹĐ b â´ÂăŞéÇÔ¸ŐˇÓĹѧĘͧąéÍ·ŐčĘŘ´ «Öč§ŕ»çąÇŐ¸ŐËҤčŇ a áĹĐb ·Őč·ÓăËéĽĹşÇˇ˘Í§¤čҤÇŇÁ¤ĹŇ´ŕ¤Ĺ×č͹¡ˇÓĹѧĘͧÁŐ¤čŇąéÍ·ŐčĘŘ´
¨ŇˇĘÁˇŇĂ
U = a + bC + eI
![]() áĹĐ
U = a + bC
áĹĐ
U = a + bC
·ÓăËéĘŇÁŇö¤ÓąÇłËҤčŇ ˘Í§ a áĹĐ b ¤×Í
![]() b = n å xi yi - ( å xi ) (å yi )
b = n å xi yi - ( å xi ) (å yi )
n å xi2 - ( å xi ) 2
=
SSxy
![]() SSxx
SSxx
![]()
![]() a = U - b C
a = U - b C
![]() â´Â·Őč C = å xI
áĹĐ U
= å yI
â´Â·Őč C = å xI
áĹĐ U
= å yI
![]() n
n
n
n
µŃÇÍÂčҧ·Őč1 ˇŇĂÇÔŕ¤ĂŇĐËěĘÁˇŇö´¶ÍÂÍÂčҧ§čŇÂ
: ĘÁÁµÔăËéĽŮé»ĂСͺˇŇĂáËč§ËąÖ觵éͧˇŇõĂǨĘÍş´ŮÇčҡŇĂăŞé¤ÇŇÁ¶Őč˘Í§â¦ÉłŇ㹷ҧâ·Ă·ŃČąěµčÍŕ´×Íą
ÁŐ¤ÇŇÁĘŃÁľŃą¸ěÍÂčҧäáѺÂÍ´˘Ň¢ͧˇÔ¨ˇŇè֧ŕˇçşµŃÇÍÂčҧÂÍ´˘ŇÂáĹШӹǹ¤ÇŇÁ¶Őč˘Í§â¦ÉłŇ㹷ҧâ·Ă·ŃČąěµčÍŕ´×Íąä´é˘éÍÁŮŴѧąŐé
ÂÍ´˘Ň (U ) ( ËąčÇ : ľŃąşŇ· ) ¨ÓąÇą¤ĂŃé§ / ŕ´×Íą˘Í§ˇŇĂâ¦ÉłŇ·Ň§â·Ă·ŃČąě (C )
260.3
5
286.1 7
279.4 6
410.8 9
438.2
12
315.3
8
656.1
11
570.0
16
426.1
13
315.0
7
10
å Ui
= ( 260.3 + 286.1 + .... + 315.0 ) =
3,866.3
i=1
10
å Ci = ( 5+7+
... +7 ) = 94
i=1
10
å CIUi = 5(260.3)+7(286.1)+...+7(315.0) =
39,539
i=1
10
å C2 = 52+72+...+72 = 994
i=1
![]()
![]() U = 260.3+286.1+...+315.0 =
3,866.3
= 386.63
U = 260.3+286.1+...+315.0 =
3,866.3
= 386.63
![]()
![]() 10 10
10 10
C
= 5+7+...+7 = 94 =
9.4
![]()
![]() 10 10
10 10
\ b = n å CiUi - (å Ci ) ( åUi )
i=1 i=1 i=1
![]() n n
n n
n å Ci 2 - (å Ci
)2
i=1
i=1
![]() =
10(39,539)-(94)(3866.3)
=
10(39,539)-(94)(3866.3)
10(994)-(94)2
![]() = 395,390-363,432.2
= 395,390-363,432.2
9940
- 8836
![]() = 31,957.8 = 28.947
= 31,957.8 = 28.947
1104
![]()
![]() \a = U
- b C
\a = U
- b C
= 386.63
- 28.95(9.4)
= 386.63-272.13 = 114.5
![]() ´Ń§ąŃéąĘÁˇŇö´¶Í¨Đŕ˘ŐÂąä´é´Ń§ąŐé
´Ń§ąŃéąĘÁˇŇö´¶Í¨Đŕ˘ŐÂąä´é´Ń§ąŐé
U = 114.5
+ 28.95 (Ci )
¶éŇá·ą¤čŇ Ci
ă´ć
ŧăąĘÁˇŇáç¨Đ¤ÓąÇłËҤčŇ U ( ÂÍ´˘ŇÂâ´Âŕ©ĹŐč ) ä´é¨ŇˇĘÁˇŇĂ
¶´¶Í¢éҧµéąĘŇÁŇö͸ԺŇÂä´éÇčŇÂÍ´˘Ň¨ĐŕľÔčÁ˘Öéą 28,950 şŇ·
ĘÓËĂŃşˇŇĂŕľÔčÁ¤ÇŇÁ¶Őč˘Í§â¦ÉłŇ·Ň§â·Ă·ŃČąě˘Ö鹨ҡŕ´ÔÁ 1
¤ĂŃé§ (b = 28.95) ¶éŇäÁčÁŐˇŇĂâ¦ÉłŇ·Ň§â·Ă·ŃČąěŕĹÂÂÍ´˘Ň¨Đŕ·čҡѺ
114,500 şŇ· (a
= 114.5 )
µŃÇÍÂčҧ·Őč 2 ¤ÍĹŃÁąě·Őč 2 áĹĐ 3
ăąµŇĂҧáĘ´§¤čҤĐáąą I.Q. (X) áĹФĐáąąˇŇĂÍčŇą·Őčä´é¨ŇˇˇŇĂĘÍş
(Y) ˘Í§ąŃˇŕĂŐÂą 18 ¤ą ¤ÍĹŃÁąě 4 áĘ´§¤čŇ X2 áĹФÍĹŃÁąě 5 áĘ´§¤čҢͧĽĹ¤Ůł XY
|
ąŃˇŕĂŐÂą¤ą·Őč |
(2) ¤Đáąą
IQ X |
(3) ¤ĐáąąˇŇĂÍčŇą Y |
(4) X2 |
(5) XY |
(6) ¤čŇ·ŐčľÂҡóěä´é Y |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
118 99 118 121 123 98 131 121 108 111 118 112 113 111 106 102 113 101 |
66 50 73 69 72 54 74 70 65 62 65 63 67 59 60 59 70 57 |
13,924 9,801 13,924 14,641 15,129 9,604 17,161 14,641 11,664 12,321 13,924 12,544 12,769 12,321 11,236 10,404 12,769 10,201 |
7,788 4,950 8,614 8,349 8,856 5,292 9,694 8,470 7,020 6,882 7,670 7,056 7,571 6,549 6,360 6,018 7,910 5,757 |
68 55 68 70 71 54 77 70 61 63 68 64 65 63 60 57 65 57 |
|
ĽĹĂÇÁ |
2,024 |
1,155 |
228,978 |
130,806 |
|
Y = (¤ĐáąąˇŇĂÍčŇą)

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() 80
80
![]()
![]()
![]()
![]() 75
75
![]()
![]()
![]()
![]()
![]() 70
70
![]()
![]()
![]()
![]()
![]() 65
65
![]()
![]()
![]()
![]()
![]() 60
60
![]()
![]()
![]() 55
55
![]() 50
50
X = (I.Q)
100 105 110 115 120 125 130 135 140 145
ĂŮ»·Őč
3 ἹŔŇľˇĂШѴˇĂШŇÂ
ŕÁ×čÍĂÇÁ¤čҵčҧ ć 㹤ÍĹŃÁąě 2, 3, 4, 5
¨Đä´éĽĹ´Ń§ąŐé

´Ń§ąŃéą ŕĘ鹶´¶ÍÂĘÓËĂŃşľÂҡóě¤čŇ Y ŕÁ×čÍ·ĂŇş¤čŇ X ŕ˘ŐÂąÍÂŮčăąĂŮ»˘Í§ĘÁˇŇĂä´éŕ»çą
![]() Y
= 0.6708 X – 11.25
Y
= 0.6708 X – 11.25
![]()
![]() ŕÁ×čÍá·ą¤čŇ X ă´ ć ăąĘٵùŐé ¨Đä´é Y «Öč§ŕ»çą¤čŇ»ĂĐÁŇł˘Í§ Y
ŕÁ×čÍá·ą¤čŇ X ă´ ć ăąĘٵùŐé ¨Đä´é Y «Öč§ŕ»çą¤čŇ»ĂĐÁŇł˘Í§ Y
ŕŞčą á·ą¤čŇ X = 118 ¨Đä´é Y = 0.6708 (118)
– 11.25 = 68
![]() ¤ÍĹŃÁąě 6 ăąµŇĂҧ
áĘ´§¤čҤĐáąąˇŇĂÍčŇą·Őč»ĂĐÁŇłä´é (Y) ¨ŇˇˇŇĂăŞéĘÁˇŇĂ
¤ÍĹŃÁąě 6 ăąµŇĂҧ
áĘ´§¤čҤĐáąąˇŇĂÍčŇą·Őč»ĂĐÁŇłä´é (Y) ¨ŇˇˇŇĂăŞéĘÁˇŇĂ
![]() Y
= 0.6708 X – 11.25
Y
= 0.6708 X – 11.25
ˇŇĂ·´ĘÍşĘÁÁµÔ°ŇąŕˇŐčÂǡѺ b
ŕ»çąˇŇĂ·´ĘÍşÇčҵŃÇá»Ă XáĹĐY ÁŐ¤ÇŇÁĘŃÁľŃą¸ěăąĹѡɳĐŕŞÔ§ŕĘéąËĂ×ÍäÁč
â´Âŕ»çąˇŇĂ·´ĘÍşĘÁÁµÔ°Ňąáşş 2 ˘éҧ
¨ŇˇĘÁˇŇö´¶ÍÂ
U =
a + bC + eI
¶éŇ b = 0
áĘ´§ÇčŇ XáĹĐY äÁčÁŐ¤ÇŇÁĘŃÁľŃą¸ěăąĹѡɳĐŕŞÔ§ŕĘéą
â´ÂÁŐĘÁÁµÔ°Ňą ¤×Í
H0
: b
= 0 ËĂ×Í XáĹĐY
äÁčÁŐ¤ÇŇÁĘŃÁľŃą¸ěăąĹѡɳĐŕŞÔ§ŕĘéą
H1
: b ¹ 0 ËĂ×Í XáĹĐY ÁŐ¤ÇŇÁĘŃÁľŃą¸ěăąĹѡɳĐŕŞÔ§ŕĘéą
![]() ʶԵԷ´ĘÍş t =
b - 0
=
b
ʶԵԷ´ĘÍş t =
b - 0
=
b
![]()
![]() sb
s
yx / Ö ssxx
sb
s
yx / Ö ssxx
![]() â´Â·Őč Syx
= ÖS (Y-Ý )2
/ n – 2
SSxx = SX2 -
(SX)2/ n
â´Â·Őč Syx
= ÖS (Y-Ý )2
/ n – 2
SSxx = SX2 -
(SX)2/ n
ˇŇĂ·´ĘÍşĘÁÁµÔ°ŇąŕˇŐčÂǡѺ a
ŕ»çąˇŇĂ·´ĘÍşÇčҵŃÇá»Ă Y=0áĹéÇ X¨Đŕ·čҡѺ
0 ËĂ×ÍäÁč â´Âŕ»çąˇŇĂ·´ĘÍşĘÁÁµÔ°Ňą
H0
: a = 0
H1
: a ¹ 0
![]() ʶԵԷ´ĘÍş t =
a - 0
ʶԵԷ´ĘÍş t =
a - 0
sa
sa
= s2
yx (1/n + x 2 / ssxx )
¤ÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍąÁҵðҹ㹡ŇĂľÂҡóě (Standard error of estimate)
¶éҢéÍÁŮĹ 2 ŞŘ´·ŐčÁŇËҤÇŇÁĘŃÁľŃą¸ěˇŃąąŃ鹤Ĺé͵ŇÁˇŃąäÁčŕ»çąŕĘ鹵ç (rxy
¹ 1) 㹡ŇĂľÂҡóě¤čҵŃÇá»ĂµŃÇËąÖ觨ҡµŃÇá»ĂÍŐˇµŃÇËąÖ觨ĐÁŐ¤ÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍąŕˇÔ´˘Öéą
¶éŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ě(rxy) ·Őč¤ÓąÇłä´éÁŐ¤čŇĘ٧
¤ÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍąˇç¨ĐąéÍ ¶éŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ě (rxy) ·Őč¤ÓąÇłä´éÁŐ¤čҵčÓ ¤ÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍąˇç¨ĐÁҡ
¤ÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍąÁҵðҹ㹡ŇĂľÂҡóě¨ĐÁŐ¤čŇÁҡąéÍÂŕ·čŇă´ ¤ÓąÇłä´é¨ŇˇĘٵùŐé
(1) ˇĂłŐľÂҡóě¤čŇ Y ŕÁ×čÍ·ĂŇş¤čŇ X
![]()
ĘٵĂ
(2) ˇĂłŐľÂҡóě¤čŇ X ŕÁ×čÍ·ĂŇş¤čŇ Y
![]()
ĘٵĂ
ŕÁ×čÍ Syx á·ą¤ÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍąÁҵðҹ㹡ŇĂľÂҡóě¤čŇ Y ŕÁ×čÍ·ĂŇş¤čŇ
X
Sy á·ą¤ÇŇÁŕşŐč§ູÁҵðҹ˘Í§¤ĐáąąŞŘ´ Y
Sxy á·ą¤ÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍąÁҵðҹ㹡ŇĂľÂҡóě¤čŇ X ŕÁ×čÍ·ĂŇş¤čŇ
Y
Sx á·ą¤ÇŇÁŕşŐč§ູÁҵðҹ˘Í§¤ĐáąąŞŘ´ X
R á·ąĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ě·Őč¤ÓąÇłä´é
˘éÍĘѧࡵ ¶éŇ rxy ÁŐ¤čŇŕ»çą 1 ¤ÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍąÁҵðҹ㹡ŇĂľÂҡóě¨ĐÁŐ¤čŇŕ»çą0
ˇŇĂÇÔŕ¤ĂŇĐË춴¶ÍÂŕŞÔ§«éÍą (
Multiple regression )
ĘÁˇŇáŇö´¶ÍÂŕŞÔ§«éÍą ( Multiple regression equation ) ÁŐĂٻẺ¤ĹéҤĹÖ§ˇŃşĘÁˇŇáŇö´¶ÍÂÍÂčҧ§čŇ ( Simple regression
equation ) ŕľŐ§áµčÇčŇĘÁˇŇö´¶ÍÂŕŞÔ§«éÍą¨ĐÁŐµŃÇá»ĂÍÔĘĂĐ C ÁҡˇÇčŇ1 µŃǢÖéąä» ĘÁÁµÔăËéąŃˇÇÔ¨ŃÂʹ㨵ŃÇá»ĂÍÔĘĂĐ C 3 µŃÇ ( C1 , C2 áĹĐ C3 ) ÇčҨĐÁռšĂĐ·şâ´ÂµĂ§µčÍÂÍ´˘Ň (U) ĘÁˇŇö´¶ÍÂŕŞÔ§«éÍąăąĂٻẺ¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§ŕĘ鹵çĘŇÁŇöŕ˘ŐÂąä´éáşş§čŇÂć
´Ń§ąŐé
U = a + b1C1 + b2C2 + b3C3 +
e
¶éŇËҡµéͧˇŇĂŕ˘ŐÂąĘÁˇŇâéҧµéą´Ń§ˇĹčŇÇÍÂčҧ¶ŮˇµéͧÍҨ¨Đŕ˘ŐÂąăËÁčä´é´Ń§ąŐé
U123 = a123 + bU1.23 C1 + bU2.13 C2 + bU3.12 C3 + e(123)
â´Â·Őč U123 ¤×Í ¤čҢͧ U ·Őč¤Ň´¤Đŕąä´é¨ŇˇĘÁˇŇö´¶ÍÂŕŞÔ§«éÍą
U ¤×Í µŃÇá»ĂµŇÁ áĹĐ C1 , C2 áĹĐ C3
¤×͵ŃÇá»ĂÍÔĘĂĐ
a123 ¤×Í ¤čŇ Intercept ˘Í§ĘÁˇŇö´¶ÍÂŕŞÔ§«éÍą
bU1.23 ¤×Í ¤čŇ Coefficient
¤čŇ C1 ăąĘÁˇŇö´¶ÍÂŕŞÔ§«éÍą ¤čŇ bU1.23 ąŐéÁŐŞ×čÍŕĂŐ¡ÍŐˇ
Ş×čÍËąÖč§ÍÂčҧŕ»çą·Ň§ˇŇĂÇčŇ Coefficient
of partial regression
bU1.23 ŕ»çą¤čŇ·ŐčáĘ´§¶Ö§ˇŇĂŕ»ĹŐčÂąá»Ĺ§˘Í§µŃÇá»ĂµŇÁ
U ŕÁ×č͵ŃÇá»ĂÍÔĘĂĐ C1
ŕ»ĹŐčÂąá»Ĺ§ä» 1 ËąčÇ ŕŢ 1 ËĹѧ U ËÁҶ֧µŃÇá»ĂÍÔĘĂĐ C1 (
Predictor variable µŃÇ·Őč
1 ) ĘčÇąŕŢ 2 áĹĐ3 ËĹѧ ¨Ř´·ČąÔÂÁąŃéą
şÍˇăËé·ĂŇşÇčŇÂѧÁŐµŃÇá»Ăµéą ËĂ×Í Predictor variable ÍŐˇ 2 µŃÇ ¤×Í C2 áĹĐ C3 ·ŐčÁŐ¤čҤ§·Őč ´Ń§ąŃéą bU2.13 áĹĐ bU3.12 ¨ĐÁŐ¤ÇŇÁËÁŇÂ㹷ӹͧŕ´ŐÂǡѹ
e(123) ¤×Í
¤čҤÇŇÁĽÔ´ľĹŇ´·ŐčŕˇŐčÂǢéͧˇŃşˇŇĂľÂҡóě¤čŇ U â´Â·ŐčÁŐ C1 , C2 áĹĐ C3 ŕ»çąµŃÇá»ĂÍÔĘĂĐ
¤čŇ»ĂĐÁŇł˘Í§Y ¤×Í
y = a+ b1 x1+b2x2
+b3x3+….+e
â´Â·Őč a ¤×Í ĂĐÂеѴ᡹ Y ˇŃşX
ŕÁ×č͡ÓËą´ăËé x1 = x2 = x3 =
0
b1, b2, b3 ŕ»çą¤čŇ«Öč§áĘ´§¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧ Y ˇŃşX áĹĐÁŐ¤ÇŇÁËÁŇÂ
´Ń§ąŐé
b1 ËÁҶ֧ ¶éŇ x1 ŕľÔčÁ˘Öéą 1 ËąčǨзÓăËé Y ŕ»ĹŐčÂąá»Ĺ§ä»
b1 ËąčÇÂ
â´Â·ŐčµŃÇá»ĂÍÔĘĂĐÍ×čąć (x2 , x3) ÁŐ¤čҤ§·Őč ĘčÇą b2 áĹĐ b3 ¨ĐÁŐ¤ÇŇÁËÁŇÂ㹷ӹͧŕ´ŐÂǡѹ
㹡óշŐčá»Ĺ§ĘŃÁ»ĂĐĘÔ·¸ÔěˇŇö´¶Í (b) ăËéŕ»çąĘŃÁ»ĂĐĘÔ·¸ÔěˇŇö´¶ÍÂÁҵðҹ
(b)¨Đŕ˘ŐÂąĘÁˇŇĂä´éŕ»çą
Zy = b1zx1
+b2zx2 +b3zx3
+…+ e
˘é͵ˇĹ§ŕş×éͧµéą˘Í§ Multiple regression
1. µŃÇ·ÓąŇÂáµčĹеŃÇáĹеŃÇá»Ăࡳ±ěÁŐ¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§ŕĘ鹵ç
2. µŃÇá»Ăࡳ±ěµéͧÁŐĹѡɳеčÍŕą×čͧ
áĹĐÍÂčҧąéͤÇĂÍÂŮčăąÁҵĂŇÍŃąµĂŔҤ
3. ¤ÇŇÁá»Ă»ĂÇą˘Í§¤ÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍą
㹷ء ć ¤čҢͧµŃÇá»Ă x ¨ĐÁŐ¤čŇŕ·čҡѹ
4. µŃǷӹҨеéͧäÁčĘŃÁľŃą¸ěˇŃąŕͧĘ٧
( äÁčŕˇÔ´ multicollinearity
)
5. ˇŇĂá»Ă¤čҢͧµŃÇá»ĂµŇÁáµčĹФčҵéͧŕ»çąÍÔĘĂШҡˇŃą
6.
ˇŇĂᨡᨧ˘Í§¤ÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍą¨Đµéͧŕ»çąNormality
ˇŇĂ·´ĘÍşĘÁÁµÔ°ŇąŕˇŐčÂǡѺĘŃÁ»ĂĐĘÔ·¸Ôě¤ÇŇÁ¶´¶ÍÂ( b)
ŕ»çąˇŇĂ·´ĘÍşÇčҵŃÇá»Ă X ÍÂčҧąéÍ 1 µŃÇ Y
ÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃşY â´ÂÁŐĘÁÁµÔ°Ňą ¤×Í
H0
: bi = 0
H1 : b i ¹ 0 ; i = 1,2 ,…,k
![]() ʶԵԷ´ĘÍş t = bi - 0
ʶԵԷ´ĘÍş t = bi - 0
sbi
ĘŃÁ»ĂĐĘÔ·¸ÔěˇŇ÷ӹҠ( Coefficient of determination ,R2)
ĘŃÁ»ĂĐĘÔ·¸ÔěˇŇĂ·ÓąŇÂ
ŕ»çąĘŃ´ĘčÇą·ŐčµŃÇá»ĂÍÔĘĂĐĘŇÁŇö͸ԺҤÇŇÁĽŃąá»Ă˘Í§µŃÇá»Ă Y ä´é ăŞéĘŃĹѡɳě R2
y.123…k
â´Â·Őč R2 = ¤ÇŇÁĽŃąá»Ăŕą×čͧ¨ŇˇÍÔ·¸ÔľĹ˘Í§X1,
X2, … Xk
![]() ¤ÇŇÁĽŃąá»Ă·Ńé§ËÁ´
¤ÇŇÁĽŃąá»Ă·Ńé§ËÁ´
= SSR/SST = (SST –SSE) / SST
R2 ŕ˘éŇăˇĹé
1
Áҡŕ·čŇäĂáĘ´§ÇčҤÇŇÁĽŃąá»Ă˘Í§µŃÇá»Ă y ¶ŮˇÍ¸ÔşŇÂä´é´éǵŃÇá»ĂÍÔĘĂĐÁҡŕ·čŇąŃéą
ĘŃÁ»ĂĐĘÔ·¸ěľËؤٳ (Multiple correlation , R )
ĘŃÁ»ĂĐĘÔ·¸ěľËؤٳ
ä´é¨ŇˇˇŇöʹĂҡ·ŐčĘͧ˘Í§ĘŃÁ»ĂĐĘÔ·¸ÔěˇŇ÷ӹҠâ´Â·ŐčĘŃÁ»ĂĐ
ĘÔ·¸ěľËؤٳáĘ´§¶Ö§¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧ
Y ˇŃş X1, X2,
… Xk ¶éŇÁŐ¤čŇŕ˘éŇăˇĹéČŮąÂěáĘ´§ÇčŇ Y ˇŃş X1,
X2, … Xk ÁŐ¤ÇŇÁĘŃÁľŃą¸ěąéÍÂÁҡ
¶éŇÁŐ¤čŇŕ·čҡѺ 0 áĘ´§ÇčŇ Y ˇŃş X1,
X2, … Xk äÁčÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃą ¶éŇ ÁŐ¤čŇŕ˘éŇăˇĹé 1 áĘ´§ÇčŇ Y ˇŃş X1, X2,
… Xk ÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃąÁҡ
ˇŇĂ·´ĘÍşˇŇ÷ӹҵŃÇá»Ăâ´ÂăŞéâ»ĂáˇĂÁ SPSS for Windows
1. ˇŇ÷ӹҵŃÇá»Ăࡳ±ě 1 µŃÇ
¨ŇˇµŃÇá»Ă·ÓąŇ 1 µŃÇ ăŞéĘ¶ÔµÔ Simple
regression
analysis
µŃÇÍÂčҧ
¶éҵéͧˇŇĂČÖˇÉŇÇčŇĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇŕ»çąµŃÇ·ÓąŇÂĂҨčŇ¢ͧ¤ĂÍş¤ĂŃÇä´éËĂ×ÍäÁč
áĘ´§ÇčŇÁŐá»Ăࡳ±ě 1
µŃÇä´éáˇč ĂҨčŇ¢ͧ¤ĂÍş¤ĂŃÇ
µŃÇá»Ă·ÓąŇ 1 µŃÇ ä´éáˇč ĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ
ĘŇÁŇöăŞéâ»ĂáˇĂÁ
SPSS for Windows ä´é´Ń§ąŐé
1ăŞé¤ÓĘŃč§
 Analyze
Analyze
Regression
Linear
¨Đä´éËąéҨʹѧáĘ´§ăąĂŮ»·Őč 1
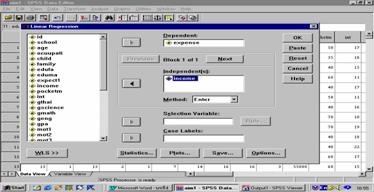
ĂŮ»·Őč 1 Linear Regression
¨ŇˇĂŮ»·Őč 4 ŕĹ×͡µŃÇá»Ăࡳ±ě 1 µŃÇ ¤×Í ĂҨčŇ¢ͧ¤ĂÍş¤ĂŃÇ ăĘčăą box ˘Í§ dependent áĹĐŕĹ×͡µŃÇá»Ă·ÓąŇ ¤×Í
ĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ ăĘčăą box ˘Í§ independent ŕĹ×͡ method
![]() 2 ŕĹ×͡ statistics ¨Đä´éËąéҨʹѧĂŮ»·Őč 2
2 ŕĹ×͡ statistics ¨Đä´éËąéҨʹѧĂŮ»·Őč 2
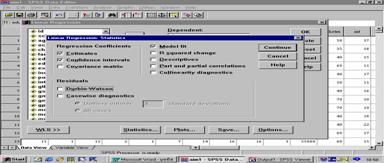
ĂŮ»·Őč 2 Linear Regression :
Statistics
![]()
![]() 3. ŕĹ×͡ʶԵԷŐčµéͧˇŇĂáĹéÇŕĹ×͡ continue ¨ĐˇĹŃşÁŇËąéҨÍŕ´ÔÁĂŮ»·Őč 1 ŕĹ×͡ OK ¨Đä´éĽĹĹŃľ¸ěăąµŇĂҧ·Őč
2-4
3. ŕĹ×͡ʶԵԷŐčµéͧˇŇĂáĹéÇŕĹ×͡ continue ¨ĐˇĹŃşÁŇËąéҨÍŕ´ÔÁĂŮ»·Őč 1 ŕĹ×͡ OK ¨Đä´éĽĹĹŃľ¸ěăąµŇĂҧ·Őč
2-4
µŇĂҧ·Őč 2 Model Summaryb
|
Model |
R |
R Square |
Adjusted
R Square |
Std.Error of the Estimate |
Durbin-Wastson |
|
1 |
.956b |
.914 |
.913 |
2105.6496 |
2.000 |
Predictors(Constant),income
of respondent
¨ŇˇµŇĂҧ·Őč
3
ËÁҤÇŇÁÇčŇ
ĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇĘŇÁŇö͸ԺҤÇŇÁĽŃąá»Ă˘Í§ĂҨčŇÂä´é 91.4%(R a =.914)
µŇĂҧ·Őč 3 ANOVAb
|
Model |
Sum
of Squares |
df |
Mean
Square |
F |
Sig. |
|
1
Regression
Residual
Total |
4166635796.39 390170915.834 4556806712.22 |
1 88 89 |
416635796 4433760.407 |
939.752 |
.000 |
a . Predictors : ( Constant ) , income of respondent
µŇĂҧ·Őč
4
ANOVA áĘ´§¶Ö§µŇĂҧÇÔŕ¤ĂŇĐËě¤ÇŇÁá»Ă»ĂÇą˘Í§ĘÁˇŇĂ
Expense
= a + b Income +
e ĘÓËĂŃşˇŇĂ·´ĘÍşĘÁÁµÔ°Ňą
H0
: Expense ¹ a + b Income +
e ËĂ×Í H0
: b = 0
H1
: Expense = a + b Income +
e ËĂ×Í H1
: b ¹0
![]()
![]() ʶԵԷ´ĘÍş F =
MSRegression = 4166635796 = 939.572
ʶԵԷ´ĘÍş F =
MSRegression = 4166635796 = 939.572
MS
Residual
4433760.407
¨Đ»ŻÔŕʸĘÁÁµÔ°Ňą H0 ¶éŇ F > F 1., 88,:.95 = 3.84 ŕą×čͧ¨Ňˇ F = 939.572 ¨Ö§»ŻÔŕʸ H0
ËĂ×͵ŃÇá»Ă expense ĘŃÁľŃą¸ěˇŃşµŃÇá»Ă income ăąĂŮ»ŕŞÔ§ŕĘéą
µŇĂҧ·Őč 4
Coefficients
|
|
Unstandardizes Coefficients |
Standardized Coefficients |
|
|
95 %
Confidence Interval for B |
||
|
Model |
B |
Std.
Error |
Beta |
t |
Sig |
Lower Bound |
Upper Bound |
|
1 ( Constant) income of respondent |
438.720 .729 |
520.416 .024 |
.956 |
.843 30.7 |
.402 .000 |
-595.498 .682 |
1472.938 .776 |
µŇĂҧ·Őč 5 Coefficients ¨ĐáĘ´§ĘŃÁ»ĂĐĘÔ·¸Ôě¤ÇŇÁ¶´¶ÍÂ
a = 438.72 şŇ· SE. (a ) = 520.416 şŇ·
b =
.729 şŇ· SE
(b) = .024 şŇ·
![]() ÚBeta = b S
x = .956
ÚBeta = b S
x = .956
S y
ˇ. ĘÁÁµÔ°Ňą H0 : b = 0
ŕ»çąˇŇĂ·´ĘÍşÇčŇĂŇÂä´éáĹĐĂҨčŇÂĘŃÁľŃą¸ěˇŃąăąĂŮ»ŕŞÔ§ŕĘéąËĂ×ÍäÁč
H1 : b ¹0
ʶԵԷ´ĘÍş : t = 30.7 Sig. ˘Í§Ę¶ÔµÔ·´ĘÍş t
= .000
¨Ö§»ŻÔŕʸ H0 ËĂ×Í b¹0
ąŃčąŕͧ
ŕÁ×čÍÁŐµŃÇá»ĂÍÔĘĂĐŕľŐ§µŃÇŕ´ŐÂÇ
ʶԵԷ´ĘÍş t2
= F áĹĐĽĹĘĂŘ»¨ĐŕËÁ×ÍąˇŃą
˘. ĘÁÁµÔ°Ňą H0 : a = 0
ŕ»çąˇŇĂ·´ĘÍşŕˇŐčÂǡѺĘčÇąˇŇõѴ᡹ Y
H1 : a ¹0
ʶԵԷ´ĘÍş t = .843
Sig ˘Í§ t
= .402 > .05 ¨Ö§ÂÍÁĂŃş H0 ËĂ×Í b = 0
´Ń§ąŃ鹼šŇĂ·´ĘÍşâ´ÂʶԵ·´ĘÍş F áĹĐ t ĘĂŘ»ä´éÇčŇĘÁˇŇäÇŇÁ¶´¶Í«Öč§áĘ´§¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧ
ĂŇÂä´éáĹĐĂҨčŇÂŕ»çą
Exp^ense = 0.729 Income
2. ˇŇ÷ӹҵŃÇá»Ăࡳ±ě 1 µŃÇ ¨ŇˇµŃÇá»Ă·ÓąŇÂÁҡˇÇčŇ 1 µŃÇ ăŞéĘ¶ÔµÔ Multiple
regression analysis
µŃÇÍÂčҧ
¶éҵéͧˇŇĂČÖˇÉŇÇčŇĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ
áĹĐŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´Ňŕ»çąµŃÇ·ÓąŇÂŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂąµčÍÇŃą
ä´éËĂ×ÍäÁč áĘ´§ÇčŇÁŐá»Ăࡳ±ě 1 µŃÇä´éáˇč
ŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂą
µŃÇá»Ă·ÓąŇ 2 µŃÇ ä´éáˇč ĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ áĹĐŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´Ň
ĘŇÁŇöăŞéâ»ĂáˇĂÁ SPSS for
Windows ä´é´Ń§ąŐé
 1ăŞé¤ÓĘŃč§
1ăŞé¤ÓĘŃč§
Analyze
Regression
Linear
¨Đä´éËąéҨʹѧáĘ´§ăąĂŮ»·Őč 3
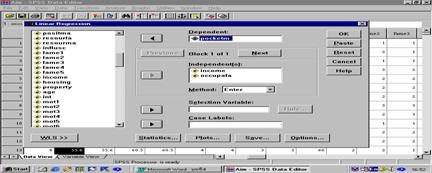
ĂŮ»·Őč 3 Linear Regression
¨ŇˇĂŮ»·Őč 6
ŕĹ×͡µŃÇá»Ăࡳ±ě 1 µŃÇ ¤×Í
ŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂą (pocketm) ăĘčăą box ˘Í§ dependent áĹĐŕĹ×͡µŃÇá»Ă·ÓąŇ ¤×Í
ĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ(income) áĹĐŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´Ň (occupafa)
ăĘčăą box ˘Í§ independent ĘčÇą˘Í§ method ŕĹ×͡enter
![]() 2 ŕĹ×͡ statistics ¨Đä´éËąéҨʹѧĂŮ»·Őč 4
2 ŕĹ×͡ statistics ¨Đä´éËąéҨʹѧĂŮ»·Őč 4
ĂŮ»·Őč 4 Linear Regression :
Statistics
3. ĂŮ»·Őč 4 ăąĘčÇą˘Í§ Regression Coefficient ŕĹ×͡ Estimates
áĹĐ Confidence interval
ăąĘčÇą˘Í§ Residuals ŕĹ×͡ Durbin-Watson
ŕĹ×͡ Model fit , R square change ,
Part and partial correlation áĹĐ Collinearity
diagostics
![]()
![]() áĹéÇŕĹ×͡ continue ¨ĐˇĹŃşÁŇËąéҨÍŕ´ÔÁĂŮ»·Őč 6 ŕĹ×͡ OK ¨Đä´éĽĹĹŃľ¸ěăąµŇĂҧ·Őč
6-10
áĹéÇŕĹ×͡ continue ¨ĐˇĹŃşÁŇËąéҨÍŕ´ÔÁĂŮ»·Őč 6 ŕĹ×͡ OK ¨Đä´éĽĹĹŃľ¸ěăąµŇĂҧ·Őč
6-10
µŇĂҧ·Őč 5

µŇĂҧ·Őč6
ŕ»çąµŇĂҧ·Őč͸ԺҶ֧ˇŇĂŕĹ×͡µŃÇá»ĂÍÔĘĂĐŕ˘éŇĘÁˇŇĂâ´ÂÇÔ¸Ő enter â´ÂÁŐŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂą (pocketm) ŕ»çąµŃÇá»ĂµŇÁ
áĹеŃÇá»ĂÍÔĘĂĐ·ŐčąÓŕ˘éŇ ¤×Í ĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ(income) áĹĐŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´Ň (occupafa)
µŇĂҧ·Őč 6
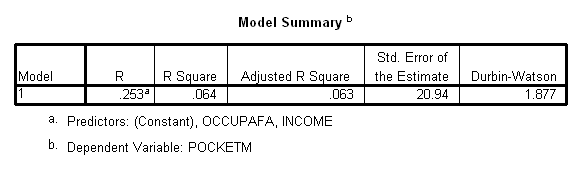
µŇĂҧ·Őč 7 ĘĂŘ»ä´é´Ń§ąŐé
R
Square = .064 ¤×ͤčŇĘŃÁ»ĂĐĘÔ·¸ÔěˇŇĂ·ÓąŇÂ
ŕ»çąĘŃ´ĘčÇą·ŐčµŃÇá»ĂÍÔĘĂĐĘŇÁŇö͸ԺҤÇŇÁĽŃąá»Ă˘Í§µŃÇá»Ăä´éÁҡąéÍÂŕ·čŇäĂ ăą·ŐčąŐéáĘ´§ÇčŇĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ(income) áĹĐŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´Ň (occupafa) ĘŇÁŇö͸ԺҤÇŇÁĽŃąá»Ă˘Í§ŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂą
(pocketm) ĂéÍÂĹĐ 6.4 ·ŐčŕËĹ×Í͸ԺŇÂä´é´éǵŃÇá»ĂÍ×čą
ĘÓËĂŃş¤čŇ
Adjusted R Square ŕ»çą¤čŇ·ŐčÁŐˇŇĂ»ĂŃşăËé¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěˇŇĂ·ÓąŇÂÁŐ¤ÇŇÁ¶ŮˇµéͧÁҡ˘Öéą
ŕą×čͧ¨ŇˇµŃÇá»ĂÍÔĘĂĐ·ŐčŕľÔčÁÁҡ˘ÖéąăąĘÁˇŇö´¶Í ¨Đ·ÓăËé¤čŇ R Square ŕľÔčÁ˘Öéą·Ńé§ć·ŐčµŃÇá»ĂÍÔĘĂĐ·ŐčŕľÔčÁÁŇąŃéąÍҨäÁčÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃşµŃÇá»ĂµŇÁ
´Ń§ąŃéą ¨Ö§µéͧÁŐˇŇĂ»ĂŃşĘٵà R Square ŕľ×čÍĹ´»ŃËҴѧˇĹčŇÇ
R ŕ»çą¤čŇĘŃÁ»ĂĐĘÔ·¸ěľËؤٳ
·ŐčáĘ´§¶Ö§¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»ĂµŇÁáĹĐŞŘ´˘Í§µŃÇá»Ă
ÍÔĘĂĐ ăą·ŐčąŐéÁŐ¤čŇŕ·čҡѺ
.253 áĘ´§ÇčŇ ŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂą
(pocketm) ˇŃş ĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ(income) áĹĐŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´Ň (occupafa) ÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃąäÁčÁҡąŃˇ
Std
Error of estimate ŕ»çą¤čҤÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍąÁҵðҹ˘Í§ˇŇĂ»ĂĐÁŇł¤čŇ«Öč§ŕ·čҡѺ
20.94 şŇ· ÁŐËąčÇÂŕ´ŐÂǡѺµŃÇá»ĂµŇÁ
Durbin-Watson ŕ»çą¤čŇʶԵԷŐč·´ĘÍş¤ÇŇÁŕ»çąÍÔĘĂТͧ¤ÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍą
«Öč§ŕ»çąŕ§×čÍąä˘ËąÖ觢ͧˇŇĂÇÔŕ¤ĂŇĐË춴¶Í 㹷ŐčąŐé ÁŐ¤čŇŕ·čҡѺ 1.877 «Öč§ÁŐ¤čŇăˇĹé 2
áĘ´§ÇčҤčҤÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍąŕ»çąÍÔĘĂШҡˇŃą
µŇĂҧ·Őč 7
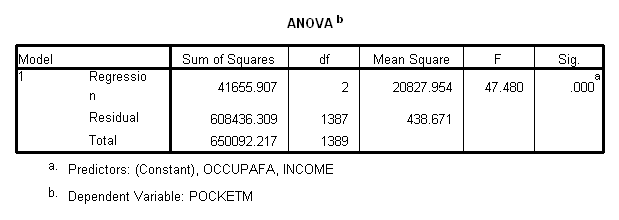
µŇĂҧ·Őč 7 ŕ»çąµŇĂҧÇÔŕ¤ĂŇĐËě¤ÇŇÁá»Ă»ĂÇą·Ň§ŕ´ŐÂÇ
«Öč§ăŞé㹡ŇĂ·´ĘÍşĘÁÁµÔ°Ňą
H0 : b 1
= b 2 = 0
H1 : b i ¹0 ÍÂčҧąéÍ 1 µŃÇ ;
i = 1,2
ăą·ŐčąŐé ä´é¤čŇF = 47.480
Sig = .000
áĘ´§ÇčŇ»ŻÔŕʸĘÁÁµÔ°Ňą H0 ĘĂŘ»ä´éÇčŇÁŐµŃÇá»ĂÍÔĘĂĐÍÂčҧąéÍ 1
µŃÇ·ŐčÁŐ¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§·ÓąŇµŃÇá»ĂµŇÁ ÍÂčҧÁŐąŃÂĘÓ¤Ń
¨Ö§µéͧ·ÓˇŇĂ·´ĘÍşµčÍä»ÇčҵŃÇá»ĂÍÔĘĂĐă´şéҧ·ŐčÁŐ¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§·ÓąŇ ŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂą
(pocketm) ăąµŇĂҧ·Őč 9
µŇĂҧ·Őč 8
|
|
Unstandardizes Coefficients |
Standardized Coefficients |
|
|
95 %
Confidence Interval for B |
Correations |
Collinearity Statistics |
|||||
|
Model |
B |
Std.
Error |
Beta |
t |
Sig |
Lower Bound |
Upper Bound |
Zero order |
Par tial |
part |
tolerance |
VIF |
|
1 (Constant) income occupafa |
41.711 7.768
E-05 .317 |
2.842 .000 .054 |
.139 .165 |
14.678 4.962 5.877 |
.000 .000 .000 |
36.137 .000 .211 |
47.286 .000 .422 |
.202 .218 |
.132 .156 |
.129 .153 |
.856 .856 |
1.168 1.168 |
Dependent Variable : POCKETM
µŇĂҧ·Őč
8
ŕ»çąµŇĂҧ·ŐčáĘ´§ˇŇĂ·´ĘÍş¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§·ÓąŇÂĂĐËÇčҧµŃÇá»ĂµŇÁˇŃşµŃÇá»ĂÍÔĘĂĐ·ŐčĹеŃÇ
ĘĂŘ»ä´é ´Ń§ąŐé
ăą Column Unstandardized Coefficient ÁŐ¤čŇ B «Öč§áĘ´§¶Ö§¤čҤ§·Őč(a) áĹФčŇĘŃÁ»ĂĐĘÔ·¸Ô춴¶ÍÂ(b) ĘčÇą Std Error ¤×ͤčҤÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍąÁҵðҹ˘Í§¤čŇ
a áĹĐb
ăą·ŐčąŐéä´é¤čҴѧąŐé
¤čҤ§·Őč a =
41.711 şŇ· SE(a) = 2.842
¤čŇĘŃÁ»ĂĐĘÔ·¸Ô춴¶Í¢ͧµŃÇá»ĂĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ(income)(b1)=.000077 şŇ·
SE(b1) =0
¤čŇĘŃÁ»ĂĐĘÔ·¸Ô춴¶Í¢ͧµŃÇá»ĂŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´Ň (occupafa) b2 = .317
şŇ·
SE (b2 )
= .054 şŇ·
ÚĘÁˇŇö´¶Í·Őč¤Ň´äÇé¨Đŕ»çą
^
POCKETM
= 41.711 + .000077 income + .317
occupafa
¨Đµéͧ·´ĘÍşµčÍÇčŇŕ»çą¨ĂÔ§ËĂ×ÍäÁč
ăą Column Standardized Coefficient áĘ´§¤čŇĘŃÁ»ĂĐĘÔ·¸Ô춴¶ÍÂÁҵðҹ
«Öč§äÁčÁŐËąčÇ ÍÂŮčăąĂŮ»˘Í§¤ĐáąąÁҵðҹ (Z
Score)
¤čŇĘŃÁ»ĂĐĘÔ·¸Ô춴¶ÍÂÁҵðҹ ˘Í§µŃÇá»ĂĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ (income) = .139
¤čŇĘŃÁ»ĂĐĘÔ·¸Ô춴¶ÍÂÁҵðҹ ˘Í§µŃÇá»ĂŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´Ň (occupafa)
= .165
áĘ´§ÇčŇÁŐ¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§·ÓąŇµŃÇá»ĂµŇÁ
¤×Í ŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂą
ÁҡˇÇčŇĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ
â´ÂăŞé¤čŇ
t ·´ĘÍşĘÁÁµÔ°ŇąŕˇŐčÂǡѺ¤čҤ§·ŐčáĹĐĘŃÁ»ĂĐĘÔ·¸Ô춴¶Í a ,
b1 áĹĐ b2
ˇ. ĘÁÁµÔ°Ňą H0 : a = 0
ŕ»çąˇŇĂ·´ĘÍşŕˇŐčÂǡѺ¤čҤ§·Őč
H1 : a ¹0
ʶԵԷ´ĘÍş t = .14.678
Sig ˘Í§
t = ..000 < .05 ¨Ö§»ŻÔŕʸ H0 ËĂ×Í
a ¹0
˘. ĘÁÁµÔ°Ňą H0 : b1 / b2
= 0
H1 : b1 / b2 ¹ 0 ËĂ×Í
H0
: ĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ äÁčÁŐ¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§·ÓąŇÂŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂąŕÁ×č͡ÓËą´ăËéŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´Ň¤§·Őč
H1
: ĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ ÁŐ¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§·ÓąŇÂŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂąŕÁ×č͡ÓËą´ăËéŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´Ň¤§·Őč
ʶԵԷ´ĘÍş : t = 4.962 Sig. ˘Í§Ę¶ÔµÔ·´ĘÍş t
= .000
¨Ö§»ŻÔŕʸ H0 ËĂ×Í b1 / b2 ¹ 0 ąŃ蹤×Í ĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ ÁŐ¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§·ÓąŇÂŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂąŕÁ×č͡ÓËą´ăËéŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´Ň¤§·Őč
¤ . ĘÁÁµÔ°Ňą H0 : b2
/ b1 =
0
H1 : b2
/ b1 ¹ 0 ËĂ×Í
H0
: ŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´ŇäÁčÁŐ¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§·ÓąŇÂŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂą
ŕÁ×č͡ÓËą´ăËéĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ
¤§·Őč
H1 :
ŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´ŇÁŐ¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§·ÓąŇÂŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂąŕÁ×č͡ÓËą´ăËéĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ ¤§·Őč
ʶԵԷ´ĘÍş : t = 5.877 Sig. ˘Í§Ę¶ÔµÔ·´ĘÍş t
= .000
¨Ö§»ŻÔŕʸ H0 ËĂ×Í b2
/ b1
¹ 0
ąŃ蹤×Í ŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´ŇÁŐ¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§·ÓąŇÂŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂą
ŕÁ×č͡ÓËą´ăËéĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ
¤§·Őč
ĘĂŘ» ¨ŇˇˇŇĂ·´ĘÍş·Ńé§ËÁ´ ĘĂŘ»ä´éÇčҵŃÇá»ĂÍÔĘĂĐ·Ńé§ 2 µŃÇ ¤×ÍĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ
áĹĐŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´ŇÁŐ¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§·ÓąŇµŃÇá»ĂµŇÁ ¤×Íŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂąÍÂčҧÁŐąŃÂĘӤѷҧʶԵԷŐčĂĐ´Ńş
0.05
ăą column
95 % Confidence
Interval for B ËÁҶ֧
¤čŇ»ĂĐÁŇłáşşŞčǧ˘Í§ĘŃÁ»ĂĐĘÔ·¸Ô춴¶Í ·ŐčĂĐ´Ńş¤ÇŇÁŕŞ×čÍÁŃčą 95 %
ăą column Correlation ÁŐ¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ěáşč§ŕ»çą
3 ĘčÇą ¤×Í
1. Zero –Order ËÁҶ֧
¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»ĂµŇÁˇŃşµŃÇá»ĂÍÔĘĂĐáµčĹеŃÇâ´ÂäÁčä´é¤Çş¤ŘÁµŃÇá»ĂÍÔĘĂеŃÇÍ×čąć
ăą·ŐčąŐéä´é¤čҴѧąŐé
¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă pocketm
ˇŃş income
=.202
¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă pocketm
ˇŃş occupafa = .218
áĘ´§ÇčҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂąˇŃşŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľ˘Í§şÔ´ŇÁŐÁҡˇÇčҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂąˇŃşĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇ
2. Partial
ËÁҶ֧ ¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ěşŇ§ĘčÇąĂĐËÇčҧµŃÇá»ĂµŇÁ(y) ˇŃşµŃÇá»ĂÍÔĘĂĐáµčĹеŃÇ(ŕŞčą x1
)â´Âä´é¤Çş¤ŘÁµŃÇá»ĂÍÔĘĂеŃÇÍ×čąć (ŕŞčą x2)·ŐčÍҨ¨ĐĘŃÁľŃą¸ěˇŃşµŃÇá»ĂµŇÁ(y) ˇŃşµŃÇá»ĂÍÔĘĂĐáµčĹеŃÇ(x1
) ăą·ŐčąŐéä´é¤čҴѧąŐé
¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă pocketm
ˇŃş income â´Â¤Çş¤ŘÁµŃÇá»Ă occupafa·ŐčÍҨ¨ĐĘŃÁľŃą¸ěˇŃş pocketm ˇŃş income ÁŐ¤čŇ
= .132
¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă pocketm
ˇŃş occupafa â´Â¤Çş¤ŘÁµŃÇá»Ă income·ŐčÍҨ¨ĐĘŃÁľŃą¸ěˇŃş
pocketm ˇŃş occupafa
ÁŐ¤čŇ = .156
3. Part ËÁҶ֧
¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ěşŇ§ĘčÇąĂĐËÇčҧµŃÇá»ĂµŇÁ(y)
ˇŃşµŃÇá»ĂÍÔĘĂĐáµčĹеŃÇ(ŕŞčą x1 )â´Âä´é¤Çş¤ŘÁµŃÇá»ĂÍÔĘĂеŃÇÍ×čąć (ŕŞčą x2)·ŐčÍҨ¨ĐĘŃÁľŃą¸ěˇŃşµŃÇá»ĂÍÔĘĂĐáµčĹеŃÇ (x1 ) ăą·ŐčąŐéä´é¤čҴѧąŐé
¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă pocketm
ˇŃş income â´Â¤Çş¤ŘÁµŃÇá»Ă occupafa·ŐčÍҨ¨ĐĘŃÁľŃą¸ě ˇŃş income ÁŐ¤čŇ = .129
¤čŇĘŃÁ»ĂĐĘÔ·¸ÔěĘËĘŃÁľŃą¸ěĂĐËÇčҧµŃÇá»Ă pocketm
ˇŃş occupafa â´Â¤Çş¤ŘÁµŃÇá»Ă income·ŐčÍҨ¨ĐĘŃÁľŃą¸ěˇŃş
occupafa ÁŐ¤čŇ = .153
ăą
column Collinearity Statistics ËÁҶ֧
¤čŇʶԵԷŐčÇŃ´¤ÇŇÁĘŃÁľŃą¸ě˘Í§µŃÇá»ĂÍÔĘĂĐ
Tolerance
= 1-R2
¶éŇÁŐ¤čҵčÓáĘ´§ÇčҵŃÇá»ĂÍÔĘĂеŃÇąŃéąÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃşµŃÇá»ĂÍÔĘĂеŃÇÍ×čąćÁҡ
VIF
= 1/ 1-R2
¶éŇÁŐ¤čŇÁҡáĘ´§ÇčҵŃÇá»ĂÍÔĘĂеŃÇąŃéąÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃşµŃÇá»ĂÍÔĘĂеŃÇÍ×čąćÁҡ
ăą·ŐčąŐéä´é¤čҴѧąŐé
Tolerance ˘Í§ income
áĹĐ occupafa
= .856 VIF =
1.168
µŇĂҧ·Őč 9
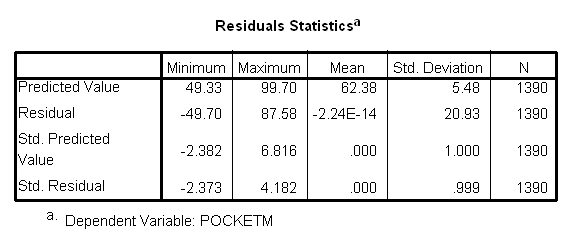 µŇĂҧ·Őč 9
ŕ»çąµŇĂҧ·ŐčăËé¤čŇʶԵÔͧ¤čҤĹŇ´ŕ¤Ĺ×čÍą
µŇĂҧ·Őč 9
ŕ»çąµŇĂҧ·ŐčăËé¤čŇʶԵÔͧ¤čҤĹŇ´ŕ¤Ĺ×čÍą
Predicted Value ËÁҶ֧ ¤čŇ»ĂĐÁŇł˘Í§µŃÇá»ĂµŇÁ
ăą·ŐčąŐé¤×ͤčŇ»ĂĐÁŇł˘Í§ŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂą ËĂ×Í Pock^etm ·ŐčÁŐ¤čŇĘ٧ĘŘ´ =
99.70
µčÓĘŘ´ = 49.33
Residual ËÁҶ֧ ¤čҤÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍą·ŐčŕˇÔ´¨ŇˇˇŇĂ»ĂĐÁŇł¤čŇ
Pocketm ´éÇ Pock^etmâ´Â·Őč
Residual =
Pocketm - Pock^etm
Std. Predicted Value ËÁҶ֧
¤čŇ»ĂĐÁŇł˘Í§µŃÇá»ĂµŇÁăą·ŐčąŐé¤×ͤčŇ»ĂĐÁŇł˘Í§ŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂą
ăąĂŮ»¤ĐáąąÁҵðҹ = Z poc^ketm
â´Â·Őč
Z
poc^ketm
= Pock^etm
- mean (Pock^etm )
![]() SD(Pock^etm )
SD(Pock^etm )
Std. Residual
ËÁҶ֧ ¶Ö§
¤čҤÇŇÁ¤ĹŇ´ŕ¤Ĺ×čÍąÁҵðҹ
ËĂ×Í Z Residual
Z Residual = Residual - mean
(Residual)
![]() SD( Residual)
SD( Residual)
ĘĂŘ»
¨ŇˇˇŇĂÇÔŕ¤ĂŇĐËěĘÁˇŇö´¶Í¢ͧµŃÇá»Ăŕ§Ôą·ŐčşŘµĂä´éä»âçŕĂŐÂą
ˇŃşĂŇÂä´é˘Í§¤ĂÍş¤ĂŃÇáĹĐŕˇŐÂõÔŔŮÁÔăąÍŇŞŐľşÔ´ŇąŃéą ľşÇčҵŃÇá»ĂÍÔĘĂĐ·Ńé§ 2 µŃÇ
ÁŐ¤ÇŇÁĘŃÁľŃą¸ěŕŞÔ§·ÓąŇ¡ѺµŃÇá»ĂµŇÁÍÂčҧÁŐąŃÂĘӤѷҧʶԵÔ
áĹĐĘŇÁŇöŕ˘ŐÂąĘÁˇŇĂăąĂŮ»˘Í§¤Đáąą´ÔşáĹĐăąĂŮ»˘Í§¤ĐáąąÁҵðҹä´é ´Ń§ąŐé
ĘÁˇŇĂăąĂŮ»˘Í§¤Đáąą´Ôş
^
POCK ETM
= 41.711
+ .000077 income + .317 occupafa
ĘÁˇŇĂăąĂŮ»˘Í§¤ĐáąąÁҵðҹ
Z poc^ketm = .139 Z income + .165 Z occupafa
áşş˝ÖˇËŃ´
1. ¨§ĂĐşŘʶԵԷŐčăŞé㹡ŇĂËҤÇŇÁĘŃÁľŃą¸ě˘Í§µŃÇá»ĂµčÍ仹Őé
1.1 ˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧÍŃą´Ńş·Őč˘Í§ŔŇľÇŇ´¨ŇˇˇĂĂÁˇŇĂ
2 ·čŇą
1.2 ˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧ¤ĐáąąŔŇÇĐĽŮéąÓˇŃşˇŇĂŕ»çą·ŐčÂÍÁĂŃş˘Í§ĽŮéăµéşŃ§¤ŃşşŃŞŇ
1.3 ˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧˇŇĂä»ŕĹ×͡µŃ駡ѺĂĐ´ŃşˇŇĂČÖˇÉŇ
1.4 ˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧˇŇĂŞÍşŕĹ蹿صşÍšѺˇŇĂŞÍş´ŮżŘµşÍĹ
1.5 ˇŇĂËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧŕľČˇŃşˇŇĂŕĂŐÂąµč͵čҧ»ĂĐŕ·Č
2. ¨§ËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧĘčÇąĘ٧ˇŃşąéÓ˹ѡ˘Í§ąÔĘÔµ
5
¤ą¨Ňˇ˘éÍÁŮŵčÍ仹Őé ľĂéÍÁá»Ĺ¤ÇŇÁËÁŇÂáĹĐ·´ĘÍşąŃÂĘӤѢͧ¤čŇĘËĘŃÁľŃą¸ě´Ń§ˇĹčŇÇ
·ŐčĂĐ´ŃşąŃÂĘӤѷŐč0.05
|
ąÔĘÔµ |
ĘčÇąĘ٧ |
ąéÓ˹ѡ |
|
1 2 3 4 5 |
160 170 165 148 155 |
49 60 55 40 50 |
3. ¨§ËҤÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧˇŇáǴÇԪҡѺ¤ĐáąąĘÍşŕ˘éŇÁËŇÇÔ·ÂŇĹŃ¢ͧąÔĘÔµ
10 ¤ą
¨Ňˇ˘éÍÁŮĹ·ŐčˇÓËą´ľĂéÍÁ·Ńé§á»Ĺ¤ÇŇÁËÁŇÂ
|
ąÔĘÔµ¤ą·Őč |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
ˇÇ´ÇÔŞŇ |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
|
¤Đáąą |
300 |
250 |
275 |
190 |
400 |
200 |
150 |
210 |
305 |
175 |
4.
ąŃˇÇԨѵéͧˇŇĂČÖˇÉŇÇčŇ·ŃČą¤µÔµčÍÇÔŞŇʶԵԨзӹҤĐáąąÇÔŞŇʶԵÔä´éËĂ×ÍäÁč
¨Ö§ĘŘčÁµŃÇÍÂčҧąÔĘÔµÁŇ 10 ¤ą
ŕˇçş˘éÍÁŮĹ·ŃČą¤µÔµčÍÇÔŞŇʶԵÔáĹФĐáąąĘ¶ÔµÔ ä´é´Ń§ąŐé
|
ąÔĘÔµ¤ą·Őč |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
·ŃČą¤µÔ |
10 |
8 |
8 |
3 |
4 |
5 |
7 |
8 |
9 |
4 |
|
¤Đáąą |
7 |
8 |
7 |
5 |
6 |
3 |
9 |
5 |
6 |
3 |
¨§ĘĂéҧĘÁˇŇ÷ӹҷŃ駤Đáąą´ÔşáĹФĐáąąÁҵðҹ
ľĂéÍÁ·´ĘÍşąŃÂĘӤѢͧ
ĘŃÁ»ĂĐĘÔ·¸ÔěˇŇö´¶ÍÂ
5.
ąŃˇˇŇĂČÖˇÉҵéͧˇŇĂČÖˇÉŇÇčŇĽĹĘŃÁÄ·¸Ôě·Ň§ˇŇĂŕĂŐÂą˘Í§ąÔĘÔµÁŐ¤ÇŇÁĘŃÁľŃą¸ěˇŃşáç¨Ů§ă¨ă˝čĘŃÁÄ·¸Ôě˘Í§ąÔĘÔµáĹĐÍŇÂآͧąÔĘÔµËĂ×ÍäÁč
¨Ö§ŕˇçş˘éÍÁŮšѺąÔĘÔµ 15 ¤ą ä´é˘éÍÁŮĹ ´Ń§ąŐé
|
ąÔĘÔµ |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
áç¨Ů§ă¨ |
8 |
10 |
12 |
15 |
18 |
20 |
18 |
16 |
14 |
12 |
10 |
18 |
17 |
16 |
15 |
|
ÍŇÂŘ |
20 |
22 |
24 |
26 |
28 |
30 |
28 |
26 |
22 |
24 |
22 |
25 |
25 |
24 |
26 |
|
¤Đáąą |
70 |
82 |
83 |
85 |
84 |
90 |
87 |
84 |
81 |
82 |
79 |
81 |
84 |
82 |
86 |
5.1
¨§ŕ˘ŐÂąĘÁˇŇö´¶ÍÂáĘ´§¤ÇŇÁĘŃÁľŃą¸ěĂĐËÇčҧĽĹĘŃÁÄ·¸Ôě·Ň§ˇŇĂŕĂŐÂą
áç¨Ů§ă¨ă˝čĘŃÁÄ·¸Ôě˘Í§ąÔĘÔµáĹĐÍŇÂآͧąÔĘÔµ
5.2 ¨§·´ĘÍş¤ÇŇÁĘŃÁľŃą¸ě㹢éÍ5.1 ·ŐčĂĐ´ŃşąŃÂĘӤѷŐč 0.05
5.3
¨§ËҤčŇĘŃÁ»ĂĐĘÔ·¸ÔěˇŇĂ·ÓąŇÂľĂéÍÁ·Ńé§Í¸ÔşŇ¤ÇŇÁËÁŇÂ