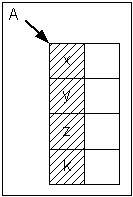
- Array
- Stack
- Queue
- Linked list
- Tree
- Heap
- Hashing array
นิยามข้อมูลแบบแถวลำดับ (Array)
ข้อมูลแบบแถวลำดับมีคุณลักษณะคือ
- มีจำนวนที่สำหรับเก็บข้อมูลจำกัด ต้องทราบจำนวนข้อมูลก่อนเริ่มใช้
(ปัจจุบันมีการใช้ Dynamic array ซึ่งพยายามลดข้อจำกัดในส่วนนี้)
- ข้อมูลแต่ละตัวมักจะเป็นประเภทเดียวกัน และมีขนาดเท่ากัน
- มีการเข้าถึงข้อมูลโดยใช้ ดรรชนี (index) ซึ่งเป็นตัวเลข
การกระทำบนข้อมูลแถวลำดับประกอบด้วย
- insert an element
- search for an element in the list
- retrieve the element
- delete the element
- check if the array is empty
- check if the array is full
- find the number of elements
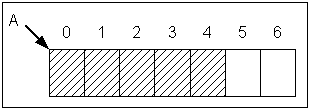
เราเขียนโครงสร้างข้อมูลแถวลำดับสำหรับจำนวนจริงได้ดังนี้
- int MAXARRAY=100;
- double A[MAXARRAY];
- int nA=0;
- การเติมข้อมูล เพื่อความรวดเร็วเราจะเติมข้อมูล ณ ตำแหน่งท้ายสุด
- insert(A, e)
- if(not full(A)) then A[nA++] = e
- การค้นหาข้อมูล
เราแบ่งการค้นหาออกเป็นสามแบบ คือ การค้นหาสมาชิก e, การค้นหาค่าสูงสุดและการค้นหาค่าต่ำสุด
- search(A, e)
- for(i = 0; i < nA; i++) {
- if(A[i] == e) then return i;
- return "not found"
- search_max(A)
- j = 0; max = A[j];
- if(nA <= 0) then return "no"
- for(i = 1; i < nA; i++) {
- if(A[i] > max) then
- j = i; max = A[j];
- return max, j;
- search_min(A)
- j = 0; min = A[j];
- if(nA <= 0) then return "no"
- for(i = 1; i < nA; i++) {
- if(A[i] < min) then
- j = i; min = A[j];
- return min, j;
- การเรียกข้อมูล
เราแบ่งเป็นสี่แบบคือ ทราบตำแหน่ง i, ทราบค่า e, ค่าที่สูงที่สุด และค่าที่ต่ำที่สุด
- get(A, i)
- return A[i]
- get(A, e)
- j = search(A, e)
- return A[j]
- get_max(A)
- [max, j] = search_max(A);
- return A[j];
- get_min(A)
- [min, j] = search_min(A);
- return A[j];
- การลบข้อมูล เราทำการลบได้สี่แบบคือ ทราบตำแหน่ง ทราบค่า ลบค่าสูงที่สุด และลบค่าต่ำที่สุด
- delete(A, i)
- e = A[i];
- A[i] = A[--nA];
- return e
- delete(A, e)
- j = search(A, e)
- A[j] = A[--nA];
- return e
- delete_max(A)
- [max, j] = search_max(A);
- A[j] = A[--nA];
- return max
- delete_min(A)
- [min, j] = search_min(A);
- A[j] = A[--nA];
- return min
- ทดสอบว่า array ว่างหรือไม่
- empty(A)
- return (nA == 0)
- ทดสอบว่า array เต็มหรือไม่
- full(A)
- return (nA-1 == MAXARRAY)
- ส่งจำนวนค่าใน array
- size(A)
- return nA
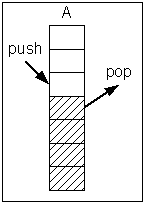
นิยามข้อมูลแบบกองซ้อน (Stack)
ข้อมูลแบบกองซ้อนมีคุณลักษณะคือ
- มีจำนวนที่สำหรับเก็บข้อมูลจำกัด ต้องทราบจำนวนข้อมูลก่อนเริ่มใช้
- ข้อมูลแต่ละตัวมักจะเป็นประเภทเดียวกัน และมีขนาดเท่ากัน
- มีการเข้าถึงข้อมูลทางด้านเดียว (Top of Stack)
การกระทำบนข้อมูลแบบกองซ้อนประกอบด้วย:
- insert an element = push(Stack, element)
- search for an element in the list
- retrieve an element and remove it = pop(Stack)
- check if the stack is empty
- check if the stack is full
- find the number of elements
เราเขียนโครงสร้างข้อมูลกองซ้อนสำหรับจำนวนจริงได้ดังนี้
- int MAXSTACK=100;
- double S[MAXSTACK];
- int tos=0;
- การเติมข้อมูล
- push(S, e)
- if(not full(S)) then S[tos++] = e
- การค้นหาข้อมูล
เราแบ่งการค้นหาออกเป็นสามแบบ คือ การค้นหาสมาชิก e, การค้นหาค่าสูงสุดและการค้นหาค่าต่ำสุด
- search(S, e)
- create tempS
- j = 0;
- while(not empty(S))
- tempe = pop(S);
- push(tempS, tempe);
- if(e == tempe) then
- while(not empty(tempS))
- tempe = pop(tempS)
- push(S, tempe)
- return j
- j = j + 1;
- while(not empty(tempS))
- tempe = pop(tempS);
- push(S, tempe);
- return "not found"
- search_max(S)
- create tempS
- j = 0
- maxi = 0
- e = pop(S)
- push(tempS, e)
- while(not empty(S))
- tempe = pop(S)
- push(tempS, tempe)
- j = j + 1;
- if(e < tempe) then
- e = tempe
- maxi = j
- while(not empty(tempS))
- tempe = pop(tempS);
- push(S, tempe);
- return e, maxi
- search_min(S)
- create tempS
- j = 0
- mini = 0
- e = pop(S)
- push(tempS, e)
- while(not empty(S))
- tempe = pop(S)
- push(tempS, tempe)
- j = j + 1;
- if(e > tempe) then
- e = tempe
- mini = j
- while(not empty(tempS))
- tempe = pop(tempS);
- push(S, tempe);
- return e, mini
- การเรียกข้อมูล
เราแบ่งเป็นสี่แบบคือ ปกติ, ทราบตำแหน่งจาก tos, ค่าที่สูงที่สุด และค่าที่ต่ำที่สุด
- pop(S)
- return S[--tos]
- retrieve(S, i)
- create tempS
- j = 0;
- while(not empty(S))
- e = pop(S)
- push(tempS, e);
- if(j == i) then
- while(not empty(tempS))
- tempe = pop(tempS)
- push(S, tempe)
- return e;
- while(not empty(tempS))
- tempe = pop(tempS);
- push(S, tempe);
- get_max(S)
- [max, j] = search_max(S);
- return max;
- get_min(S)
- [min, j] = search_min(S);
- return min;
- การลบข้อมูล เราทำการลบได้สี่แบบคือ ปกติ ทราบตำแหน่ง ลบค่าสูงที่สุด และลบค่าต่ำที่สุด
- pop(S)
- return S[--tos]
- pop(S, i)
- create tempS
- j = 0;
- while(not empty(S))
- e = pop(S)
- push(tempS, e);
- if(j == i) then
- pop(tempS)
- while(not empty(tempS))
- tempe = pop(tempS)
- push(S, tempe)
- return e;
- while(not empty(tempS))
- tempe = pop(tempS);
- push(S, tempe);
- pop_max(S)
- [max, j] = search_max(S);
- pop(S, j)
- return max
- pop_min(S)
- [min, j] = search_min(S);
- pop(S, j)
- return min
- ทดสอบว่า stack ว่างหรือไม่
- empty(S)
- return (tos == 0)
- ทดสอบว่า stack เต็มหรือไม่
- full(S)
- return (tos-1 == MAXSTACK)
- ส่งจำนวนค่าใน stack
- size(S)
- return tos
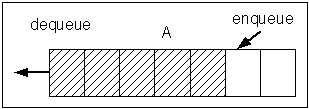
นิยามข้อมูลแบบแถวคอย (Queue)
ข้อมูลแบบแถวคอยมีคุณลักษณะคือ
- มีจำนวนที่สำหรับเก็บข้อมูลจำกัด ต้องทราบจำนวนข้อมูลก่อนเริ่มใช้
- ข้อมูลแต่ละตัวมักจะเป็นประเภทเดียวกัน และมีขนาดเท่ากัน
- มีการเข้าถึงข้อมูลสองทาง (Head and Tail)
การกระทำบนข้อมูลแบบแถวคอยประกอบด้วย:
- insert an element: enqueue(Queue, element)
- search for an element in the list
- retrieve an element and remove it: dequeue(Queue)
- check if the queue is empty
- check if the queue is full
- find the number of elements
นิยามข้อมูลแบบรายการโยง(Linked list)
ข้อมูลแบบรายการโยงมีคุณลักษณะคือ
- ใช้ตัวชี้ (pointer) ซึ่งสามารถขยายจำนวนข้อมูลอย่างไม่มีกำหนด (ข้อจำกัดขึ้นอยู่กับจำนวนหน่วยความจำที่มีทั้งหมด)
- ข้อมูลแต่ละตัวมักจะเป็นประเภทเดียวกัน แต่สามารถมีขนาดที่ต่างกันได้
- มีการเข้าถึงข้อมูลโดยการไล่ตามตัวชี้ (pointer)
- สามารถเชื่อมโยงแบบทางเดียว หรือสองทางก็ได้
การกระทำบนข้อมูลแบบรายการโยงประกอบด้วย:
- insert an element
- search for an element in the list
- retrieve an element
- remove an element
- check if the linked list is empty
- find the number of elements
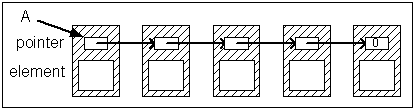 (Linked list)
(Linked list)
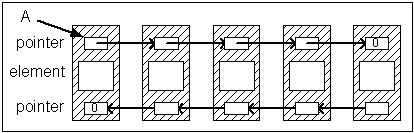 (Doubly-linked list)
(Doubly-linked list)
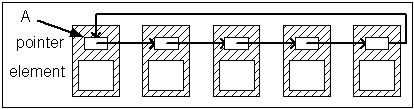 (Circularly-Linked list)
(Circularly-Linked list)
นิยามข้อมูลแบบต้นไม้(Tree)
ข้อมูลแบบต้นไม้จะมีลักษณะเป็นกราฟ (Graph) ซึ่งสำหรับกราฟ จะมีความยุ่งยากและ
ซับซ้อนในการจัดเก็บ เราจะสนใจการเก็บต้นไม้ในลักษณะของรายการโยงที่ไม่ใช่ linear ข้อมูลแบบต้นไม้มีคุณลักษณะคือ
- ใช้ตัวชี้ (pointers) ที่มากกว่าหนึ่ง สามารถขยายจำนวนข้อมูลอย่างไม่มีกำหนด (ข้อจำกัดขึ้นอยู่กับจำนวนหน่วยความจำที่มีทั้งหมด)
- ข้อมูลจะถูกเก็บไว้ที่ จุดต่อ (node) โดยจะมี จุดต่อราก (root node) เป็นจุดยอดที่สามารถเข้าถึงข้อมูลทุกค่าในต้นไม้ได้
- ต้นไม้หนึ่งต้นจะต้องมีการเชื่อมโยงกันตลอด (connected)
- ในแต่ละจุดต่อ (node) จะประกอบไปด้วยข้อมูลจริง และชุดของตัวชี้ (pointers) ซึ่งถ้ามีอยู่ 2 ตัวชี้ทั้งต้นก็จะถูกเรียกว่า binary tree
หรือถ้ามีอยู่ 3 ตัวชี้ทั้งต้นก็จะถูกเรียกว่า ternary tree
- ต้นไม้จะมีความสูง (height) ซึ่งนิยามเป็นจำนวนด้านที่มากที่สุดที่นับจาก จุดต่อรากมาถึงใบ (leaf) โดยที่ใบของต้นไม้คือ จุดต่อที่ไม่มี
การแตกกิ่งออกจากจุดต่อนั้น
- ความลึกของจุดต่อ (depth) นิยามเป็นจำนวนด้านทั้งหมดที่ใช้จาก จุดต่อรากจนถึงจุดต่อนั้น
- ระดับของจุดต่อ (level) นิยามเป็นค่าของความสูงของต้นไม้ลบด้วยความลึกของจุดต่อนั้น
- มีการเข้าถึงข้อมูลโดยการไล่ตามตัวชี้ (pointer) ซึ่งเรียกว่า tree traversals มีอยู่ 3 ประเภทคือ
- preorder traversal มีการกระทำที่จุดต่อนั้น ตามด้วยจุดต่อของต้นไม้ย่อยจากซ้ายไปขวา
- inorder traversal มีการกระทำจุดต่อของต้นไม้ย่อยทางซ้ายและตามด้วยจุดต่อนั้น แล้วจึงกระทำกับจุดต่อของต้นไม้ย่อยทางขวาไล่มา
- postorder traversal มีการกระทำจากจุดต่อของต้นไม้ย่อยจากซ้ายมาขวาและจบที่จุดต่อนั้น
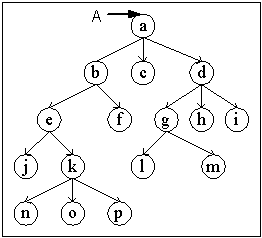
- ต้นไม้มีคุณสมบัติพิเศษที่น่าสนใจคือ
- ต้นไม้ที่มี n จุดยอดจะมีกิ่งอยู่ n-1 กิ่ง
- ถ้ามีการเพิ่มด้านในต้นไม้โดยไม่มีการเพิ่มจุดยอด จะทำให้เกิดวัฏจักร (cycle) เพียงหนึ่งวัฏจักรและที่มีด้านนั้นเป็นด้านหนึ่งในวัฏจักร
- ถ้ามีการเอาด้านใดด้านหนึ่งออกจากต้นไม้ ต้นไม้ต้นนี้จะไม่มีการเชื่อมโยงในทุกจุดอีกต่อไปทำให้เกิดป่า (forest)
การกระทำบนข้อมูลแบบต้นไม้ประกอบด้วย:
- insert an element
- search for an element in the tree
- retrieve an element
- remove an element
- check if the tree is empty
- find the number of elements
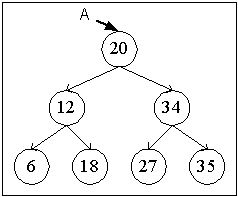 (Tree)
(Tree)
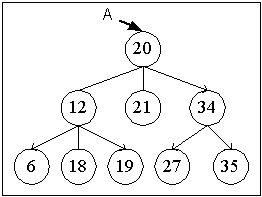 (Ternary tree)
(Ternary tree)
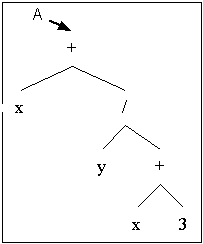 (Binary tree)
(Binary tree)
นิยามข้อมูลแบบฮีป(Heap)
ข้อมูลแบบฮีปเป็นต้นไม้แบบทวิภาคบริบูรณ์ (Complete binary tree) ซึ่งจะเน้นการหาสมาชิกที่มีค่าน้อยที่สุด (มากที่สุด)
และการเพิ่มสมาชิกในกองฮีป ข้อมูลแบบฮีปมีคุณลักษณะคือ
- เป็นต้นไม้แบบทวิภาคบริบูรณ์ (Complete binary tree)
- ข้อมูลที่อยู่ ณ จุดต่อใดๆ จะมีค่าน้อยกว่าหรือเท่ากับค่าของจุดต่อของต้นไม้ย่อยทั้งสองข้าง
- ข้อมูลที่อยู่ที่จุดต่อรากจะมีค่าน้อยที่สุดเสมอ
- มักใช้ ตัวแปรแบบแถวลำดับในการสร้างโดยสามารถคำนวณดรรชนีของลูกทางซ้าย (left child) และลูกทางขวา (right child) ได้ดังนี้
- ดรรชนีของจุดต่อที่เป็นจุดให้กำเนิด (parent) ของจุดต่อที่ดรรชนี n คำนวณได้จาก จำนวนเต็มที่มากที่สุดที่น้อยกว่าหรือเท่ากับ (n-1)/2
- ดรรชนีของลูกทางซ้ายของจุดต่อที่ดรรชนี n คำนวณได้จาก 2*n+1
- ดรรชนีของลูกทางขวาของจุดต่อที่ดรรชนี n คำนวณได้จาก 2*$n + 2
การกระทำบนข้อมูลแบบฮีปประกอบด้วย:
- insert an element = $heap->add(element);
- Heapup ปรับข้อมูลฮีปโดยพิจารณาจากปมนั้นขึ้นบน
- Heapdown ปรับข้อมูลฮีปโดยพิจารณาจากปมนั้นลงมา (heapify)
- retrieve the smallest element
- remove the smallest element
- merge two heaps
- remove an element from the heap
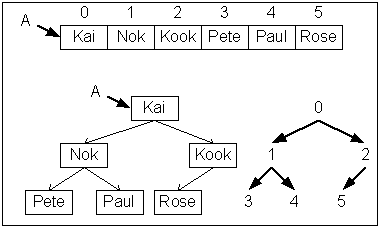
นิยามข้อมูลแบบแฮช(Hashing array)
ข้อมูลแบบแฮช เป็นข้อมูลในลักษณะแถวลำดับที่มีการใช้ดัชนีจากกลุ่มตัวอักขระ
มีอีกชื่อหนึ่งที่นิยมใช้คือ associative array ข้อมูลแบบแฮชมีคุณลักษณะคือ
- มีจำนวนที่สำหรับเก็บข้อมูลจำกัด ควรทราบจำนวนข้อมูลก่อนเริ่มใช้
- ข้อมูลแต่ละตัวต้องมี key ซึ่งเป็นข้อมูลชนิดเดียวกัน สำหรับข้อมูลอื่นมีขนาดต่างกันได้
- มีการเข้าถึงข้อมูลโดยการใช้ key
การกระทำบนข้อมูลแบบแฮชประกอบด้วย:
- insert an element
- retrieve an element
- remove an element:
- find the number of elements